计算机网络基础
网址
Url:统一资源定位符
协议 :// web服务器名 / 目录名 / … / 文件名
如:http://www.baidu.com/dir1/dir2/file.html
/ 根目录
|
|—dir1/
| |
| |—dir2/
| |
| |—file.html
|—dir3/
|
|—file2.html
浏览器的第一步就是对URL进行解析
请求消息和响应消息
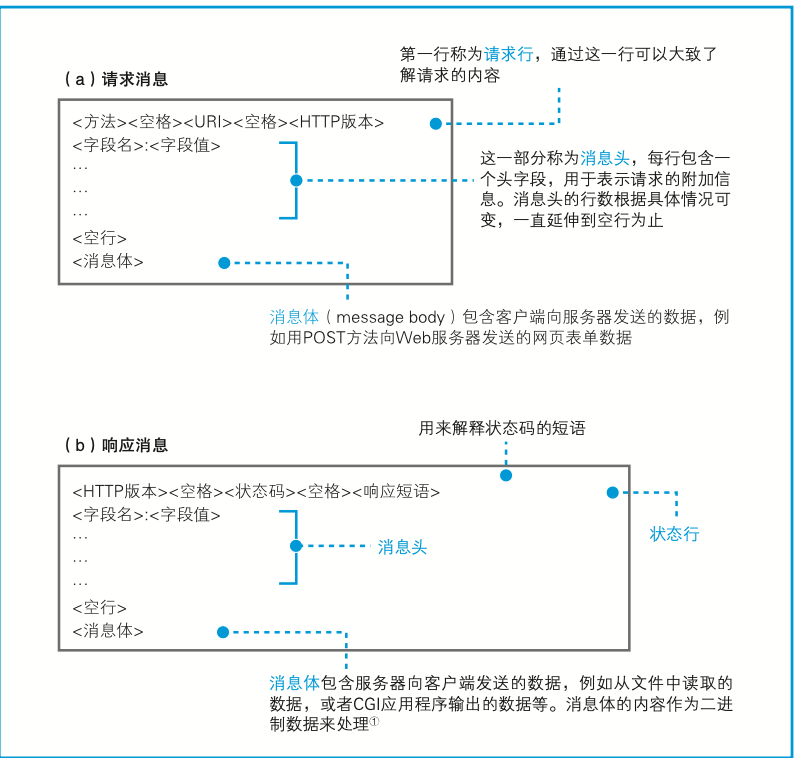
Http主要的头字段
| 头字段类型 | 含义 |
|---|---|
| Date | 请求和响应生成的日期 |
| Connection | 设置发送响应后TCP连接是否继续保持的通信选项 |
| Cache-Control | 控制缓存的相关信息 |
| 以上为通用头 | 适用于请求和响应消息的头字段 |
| Authorization | 身份认证数据 |
| User-Agent | 客户端软件的名称和版本号等相关信息 |
| Accept | 客户端支持的数据类型 |
| 以上为请求头 | 用于表示请求消息的附加信息的头字段 |
| Server | 服务器程序的名称和版本号等相关信息 |
| Location | 表示信息的准确位置,当请求的URL为相对路径时,这个字段用来返回绝对路径 |
| 以上为响应头 | 用来表示响应消息和附加信息的头字段 |
| Allow | 表示指定的URL支持的方法 |
| Content-Encoding | 当消息体经过压缩等编码处理时,表示其编码格式 |
| Content-Length | 表示消息体的长度 |
| Expires | 表示消息的有效期 |
| 以上是实体头 | 表示实体(消息体)等附加信息的头字段| |
HTTP状态码
| 状态码 | 含义 |
|---|---|
| 1XX | 告知请求的处理进度和情况 |
| 2XX | 表示请求正常处理完毕 |
| 3XX | 表示请求的处理需要进一步的操作 |
| 4XX | 客户端错误 |
| 5XX | 服务器错误 |
一条请求消息中只能写一个URL,如果需要获取多个文件,必须对每个文件单独发送一条请求
DNS
IP地址和子网掩码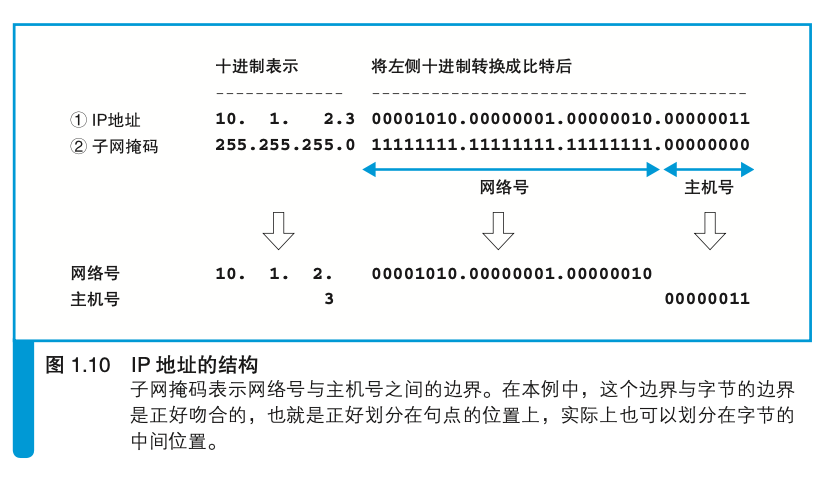
主机号全0表示整个子网,全1表示广播,即向子网上所有的设备发送包
对于DNS服务器,我们的计算机上一定有相应的DNS客户端,而相当于DNS客户端的部分称为DNS解析器,或者简称解析器。通过DNS查询IP地址的操作称为域名解析,因此负责执行解析(resolution)这一操作的就叫解析器(resolver)了。
根据域名查询IP地址时,浏览器会使用Socket库中的解析器调用解析器后,解析器会向DNS服务器发送查询消息,然后 DNS服务器会返回响应消息。响应消息中包含查询到的IP地址,解析器会取出IP地址,并将其写入浏览器指定的内存地址中。
解析器工作流程如下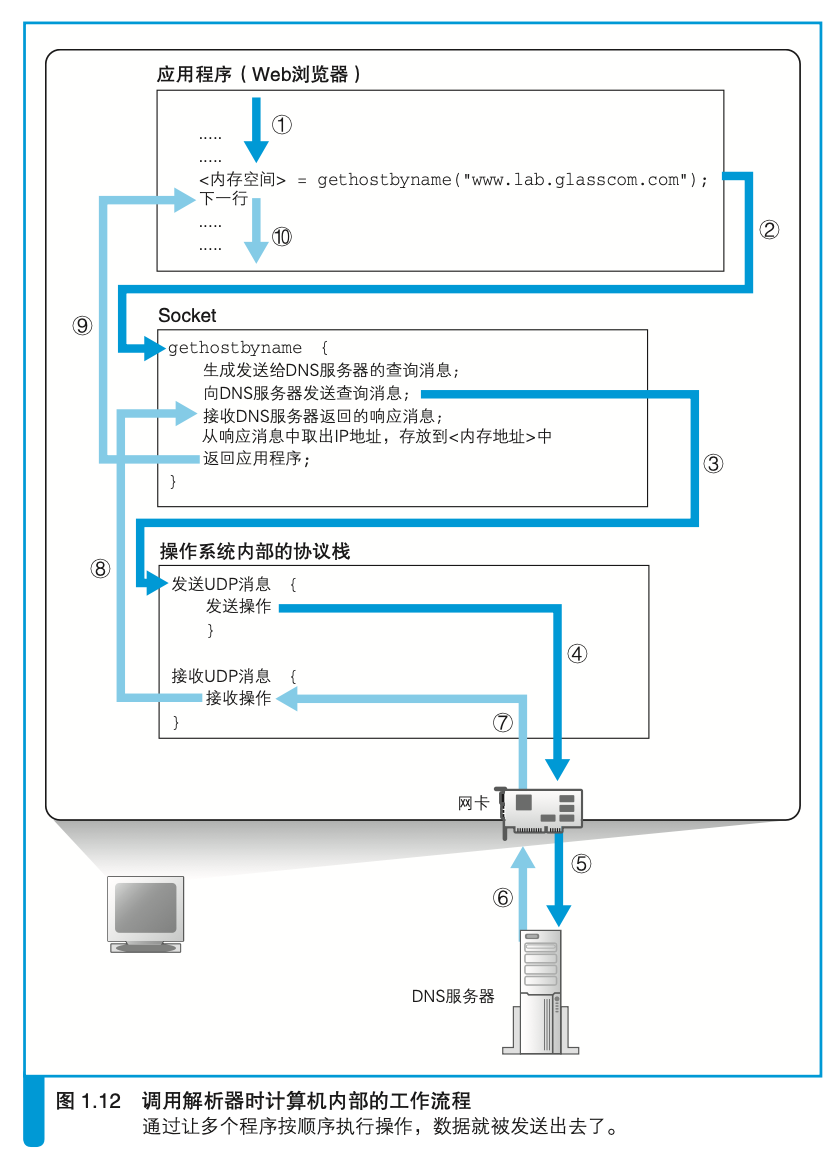
只有一个DNS服务器是不够的,因为如果只有一个DNS服务器,那么当这个服务器出现故障时,整个网络就会瘫痪。因此,DNS服务器是分布式的,分布在全球各地。DNS服务器之间会相互转发查询消息,直到找到查询的域名为止。
DNS服务器的层次结构:
- 根域名服务器
- 顶级域名服务器
- 权威域名服务器
- 本地域名服务器
DNS可以通过递归查询和迭代查询来查询域名对应的IP地址。
递归查询
迭代查询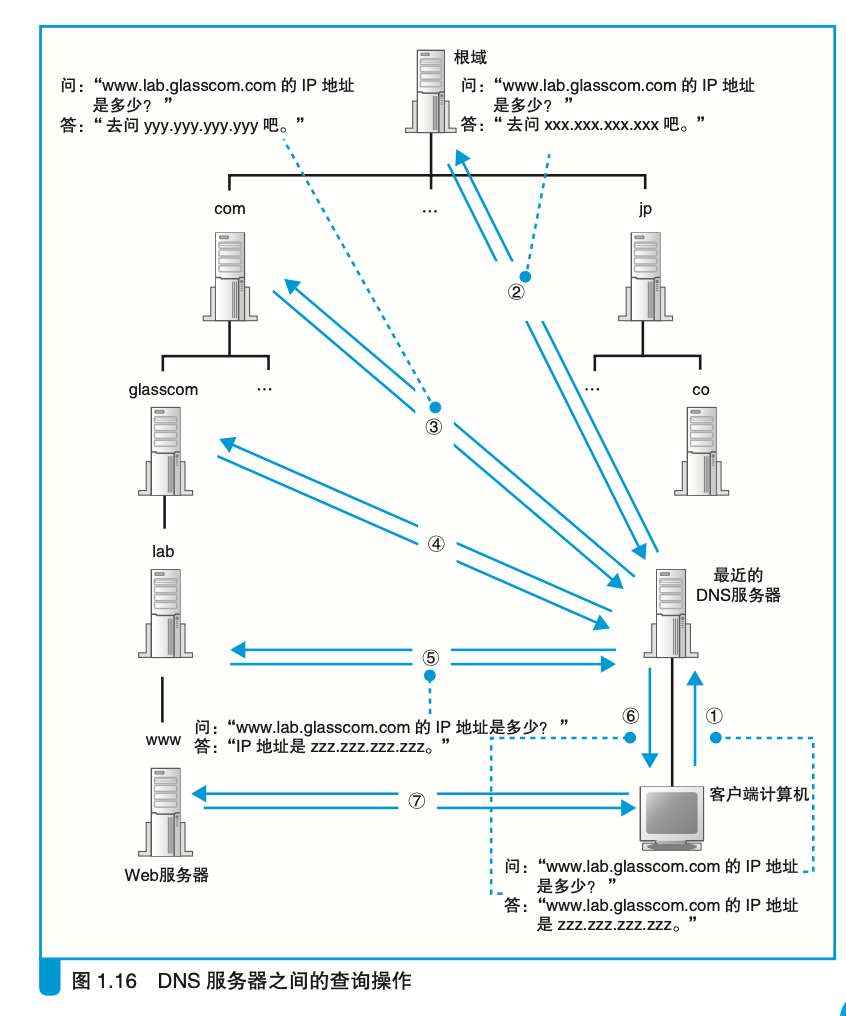
为了加快DNS服务器的响应,DNS服务器会将查询结果进行缓存,这样下次再查询相同的域名时,就可以直接返回查询结果,而不用再次查询。并且,当要查询的域名不存在时,“不存在”这一响应结果也会被缓
存。这样,当下次查询这个不存在的域名时,也可以快速响应。
但是,信息被缓存后,原本的注册信息可能会发生改变,这时缓存中的信息就有可能是不正确的。因此,DNS服务器中保存的信息都设置有一个有效期,当缓存中的信息超过有效期后,数据就会从缓存中删除。而且,在对查询进行响应时,DNS服务器也会告知客户端这一响应的结果是来自缓存中还是来自负责管理该域名的 DNS 服务器。
但是DNS查询无认证机制,在查询过程中,黑客可能会伪造错误的IP返回,导致域名对应错误的IP地址,DNS缓存了错误的IP,这就是DNS污染。可以使用DOH(DNS over HTTP)技术,将DNS查询增加认证机制,防止DNS污染。DNS劫持:DNS服务器的映射表中,直接写入了错误的IP记录。
委托协议栈发送消息
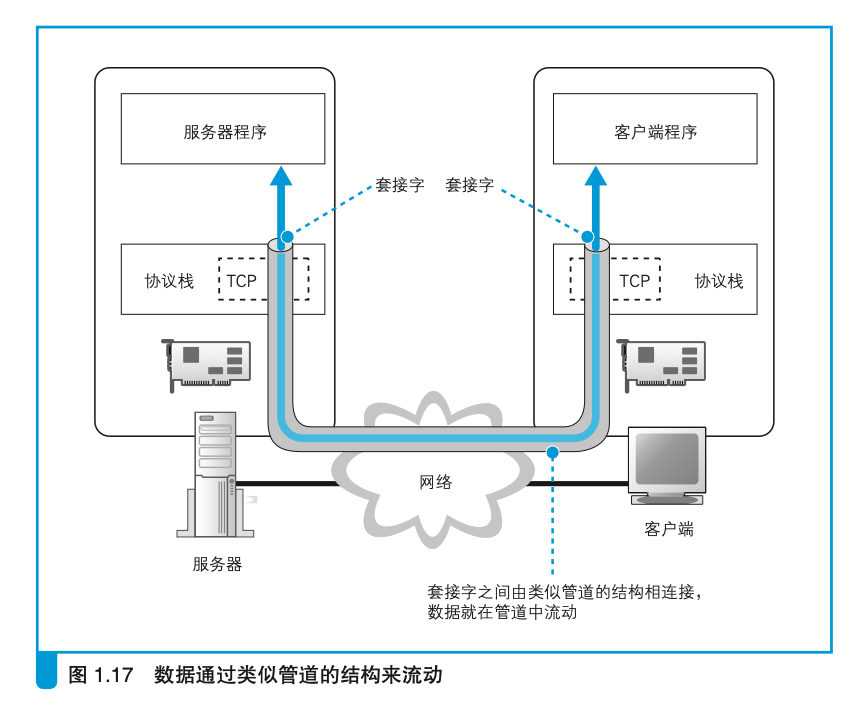
首先,服务器一方
先创建套接字, 然后等待客户端向该套接字连接管道A。当服务器进入等待状态时,客户端就可以连接管道了。具体来说,客户端也会先创建一个套接字,然后从该套接字延伸出管道,最后管道连接到服务器端的套接字上。当双方的套接字连接起来之后,通信准备就完成了。接下来,只要将数据送入套接字就可以收发数据了。
当数据全部发送完毕之后,连接的管道将会被断开。管道在连接时是由客户端发起的,但在断开时可以由客户端或服务器任意一方发起A。其中一方断开后,另一方也会随之断开,当管道断开后,套接字也会被删除。
大致可以分为4个阶段
- 创建套接字 (创建套接字阶段)
- 将管道连接到服务器端的套接字上(连接阶段)
- 通过套接字收发数据(通信阶段)
- 断开管道并删除套接字(断开阶段)
收发数据大致如下
TCP/IP协议栈
最早的 TCP/IP 协议原型设计相当于现在的TCP和IP合在一起的样子,后来才拆分成为TCP和IP两个协议。
TCP/IP软件采用分层结构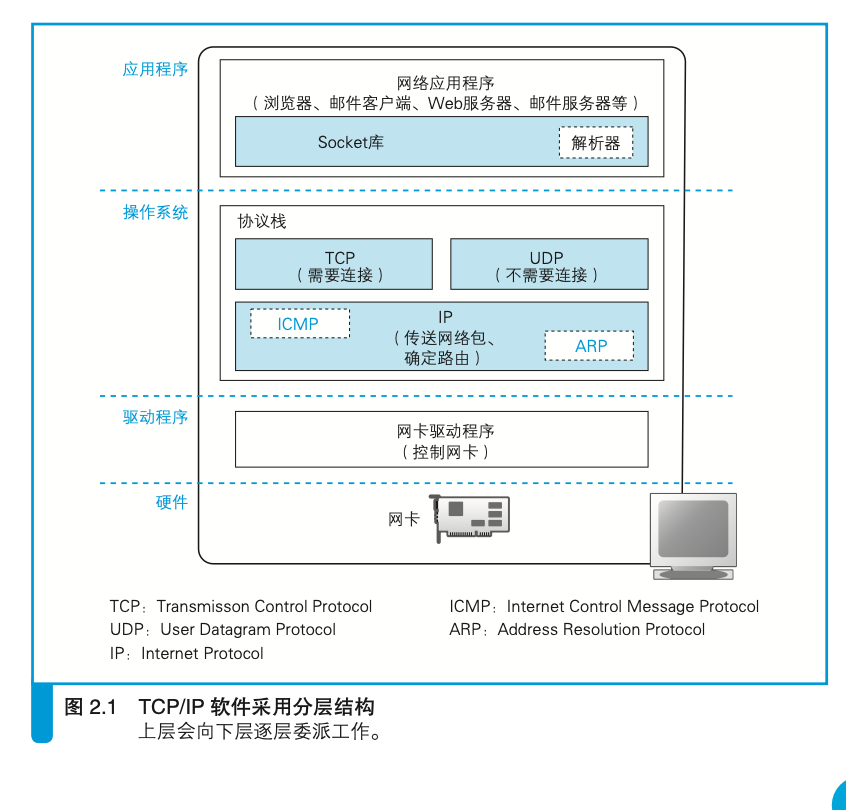
浏览器、邮件等一般应用程序收发数据时用TCP;DNS查询等收发较短的控制数据时用UDP
在和和服务器的通信结束之后,用来通信的套接字也就不会再使用了,这时我们就可以删除这个套接字了。不过,套接字并不会立即被删除,而是会等待一段时间之后再被删除。等待这段时间是为了防止误操作。
如果这时客户端的套接字已经删除了,套接字被删除,那么套接字中保存的控制信息也就跟着消失了,套接字对应的端口号就会被释放出来。这时,如果别的应用程序要创建套接字, 新套接字碰巧又被分配了同一个端口号 B, 而服务器重发的 FIN 正好到达,于是这个 FIN 就会错误地跑到新套接字里面,新套接字就开始执行断开操作了。之所以不马上删除套接字,就是为了防止这样的误操作。至于等待多长时间,和包重传的操作方式有关
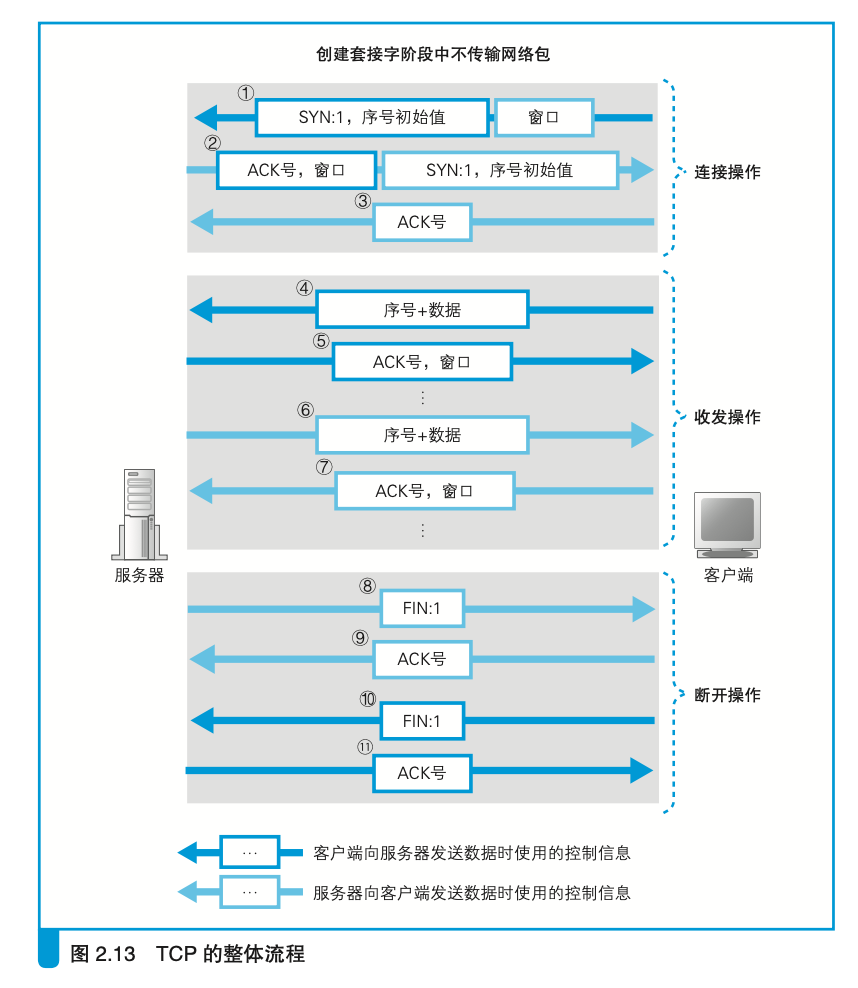
TCP的整体流程