DeepLearning
建议先学完机器学习再学深度学习,深度学习中的内容很多都是机器学习的延伸,如果没有机器学习的基础,很多概念会很难理解。
深度学习基础
随机初始化参数
在深度学习中,我们需要随机初始化参数,而不是全部初始化为0,因为如果全部初始化为0,那么每一层的参数都是一样的,那么每一层的输出也是一样的,那么多层网络就没有意义了,因此我们需要随机初始化参数。
乘以0.01是为了保证参数的值不会太大,如果太大,那么激活函数的梯度就会很小,导致梯度消失。
说神经网络的层数时,一般不包括输入层,只包括隐藏层和输出层。
训练集、验证集、测试集
在深度学习中,我们需要将数据集分为训练集、验证集、测试集,训练集用来训练模型,验证集用来调整超参数,测试集用来测试模型的性能。
对于小数据集,训练集和验证集的比例一般为7:3,训练集、验证集、测试集的比例一般为6:2:2。
对于大数据集,训练集和验证集的比例一般为98:2,训练集、验证集、测试集的比例一般为98:1:1。
划分数据集时,要保证训练集和验证集、测试集的数据分布一致,即训练集和验证集、测试集的数据来自同一个分布。
随机失活正则化(Dropout regularization)
Dropout是一种正则化技术,它可以减少过拟合,它的原理是在每一次迭代中,随机关闭一些神经元,这样就可以减少神经元之间的依赖,从而减少过拟合。
特征归一化
如果特征的取值范围差异很大,那么就需要对特征进行归一化,否则会导致梯度下降很慢。例如,如果一个特征的取值范围是0到1000,另一个特征的取值范围是0到1,那么第一个特征的梯度就会比第二个特征的梯度大1000倍,这样就会导致梯度下降很慢。
归一化的方法有两种:
- 最大最小归一化
- 均值方差归一化
最大最小归一化的公式为:
均值方差归一化的公式为:
梯度消失和梯度爆炸
梯度消失和梯度爆炸是深度学习中的两个常见问题,梯度消失是指在反向传播过程中,梯度越来越小,导致梯度下降很慢,梯度爆炸是指在反向传播过程中,梯度越来越大,导致梯度下降很快。
梯度检查
梯度检查是用来检查反向传播是否正确的,它的原理是使用数值逼近来计算梯度,然后将数值逼近的梯度和反向传播计算的梯度进行比较,如果差距很小,那么就说明反向传播计算的梯度是正确的。
梯度检查的近似公式为:
其中,是一个很小的数,例如。
检查梯度时候正确的公式为:
其中,是数值逼近的梯度,是反向传播计算的梯度。当这个值小于时,就说明梯度计算正确。
指数加权平均
指数加权平均是一种平滑技术,它的原理是使用指数加权平均来平滑数据,从而减少噪声的影响。
指数加权平均的公式为:
其中,是第t次迭代的平均值,是平滑系数,是第t次迭代的值。
指数加权平均的初始值为:
指数加权平均的偏差修正为:
带动量的梯度下降
带动量的梯度下降是一种优化算法,它的原理是使用指数加权平均来计算梯度,从而减少梯度的震荡,加快梯度下降。
带动量的梯度下降的公式为:
其中,是w的梯度的指数加权平均,是b的梯度的指数加权平均,是平滑系数,一般取0.9,是学习率。
带动量的梯度下降的初始值为:
RMSProp
RMSProp是一种优化算法,它的原理是使用指数加权平均来计算梯度的平方,从而减少梯度的震荡,加快梯度下降。
RMSProp的公式为:
其中,是w的梯度的平方的指数加权平均,是b的梯度的平方的指数加权平均,是平滑系数,是学习率。
RMSProp的初始值为:
Adam
Adam是一种优化算法,它的原理是结合带动量的梯度下降和RMSProp,从而减少梯度的震荡,加快梯度下降。
Adam的公式为:
其中,是w的梯度的指数加权平均,是b的梯度的指数加权平均,是w的梯度的平方的指数加权平均,是b的梯度的平方的指数加权平均,是平滑系数,一般取0.9,是平滑系数,一般取0.999,是学习率。
Adam的初始值为:
学习率衰减
学习率衰减是一种优化算法,它的原理是随着迭代次数的增加,逐渐减小学习率,从而减少震荡,加快梯度下降。
学习率衰减的公式为:
其中,是学习率,是衰减率,是迭代次数,是初始学习率。
超参数调整
超参数调整是一种优化算法,它的原理是使用网格搜索或随机搜索来调整超参数,从而减少震荡,加快梯度下降。
批量归一化
批量归一化是一种正则化技术,它的原理是在每一层的激活函数之前,对激活函数的输入进行归一化,从而减少梯度消失,加快梯度下降。
批量归一化的公式为:
其中,是均值,是方差,是一个很小的数,例如,是缩放参数,是平移参数。
批量归一化的初始值为:
计算机视觉
卷积神经网络
卷积神经网络是一种神经网络,它的原理是使用卷积层和池化层来提取图像的特征,然后使用全连接层来分类。
卷积核(filter)
卷积核是卷积神经网络中的一个重要概念,它的原理是使用卷积核来提取图像的特征。
卷积核的大小一般为奇数,例如3、5、7,卷积核的大小越大,提取的特征就越多,但是计算量也就越大。
卷积核的个数一般为2的幂次方,例如32、64、128,卷积核的个数越多,提取的特征就越多,但是计算量也就越大。
Padding
Padding是卷积神经网络中的一个重要概念,它的原理是在图像的边缘填充一圈0。
卷积步长
卷积步长是卷积神经网络中的一个重要概念,它的原理是在卷积过程中,卷积核每次移动的距离。
卷积层
卷积层的两个重要原则是:平移不变性和局部性。
平移不变性是指图像的平移不会影响卷积层的输出。
局部性是指卷积层的输出只与卷积核的大小有关,与图像的大小无关。
卷积层就是使用卷积核来提取图像的特征。
卷积层的输入到输出的计算公式为:
其中,是输出的高度,是输入的高度,是卷积核的大小,是填充的大小,是卷积步长,是输出的宽度,是输入的宽度。
卷积核的通道数和输入的通道数必须相同。因此,如果只有一个卷积核,那么输出的通道数就是1,如果有多个卷积核,那么输出的通道数就是卷积核的个数。
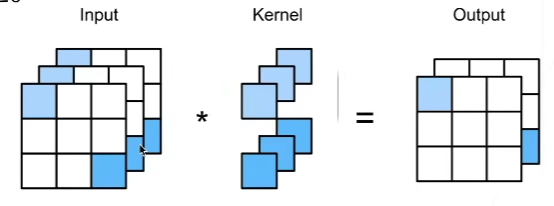
输入X有3个通道,有2个卷积核的通道为3,那么输出Y有2个通道。
池化层
池化层是卷积神经网络中的一个重要概念,它的原理是使用池化层来减少图像的大小,从而减少计算量。
池化层的类型有两种:
- 最大池化层
- 平均池化层
最大池化层的原理是在池化过程中,取池化区域中的最大值作为池化后的值。
平均池化层的原理是在池化过程中,取池化区域中的平均值作为池化后的值。
1x1卷积
1x1卷积是卷积神经网络中的一个重要概念,它的原理是使用1x1的卷积核来提取图像的特征。
1x1卷积的作用是减少图像的通道数,从而减少计算量。
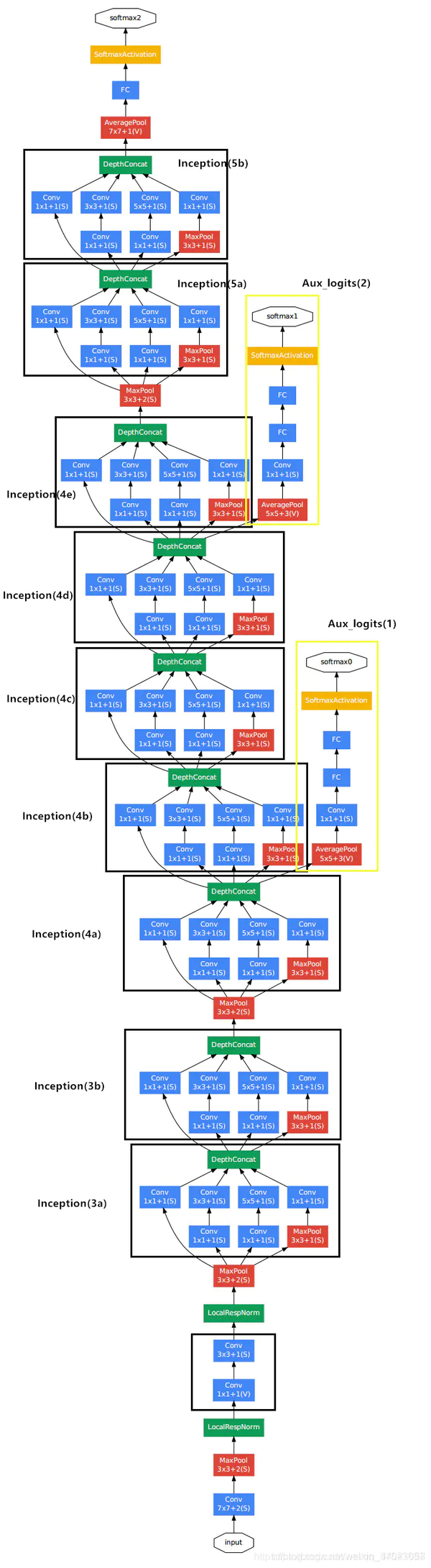
Inception模块
Inception模块是卷积神经网络中的一个重要概念,它的原理是使用多个卷积核来提取图像的特征,然后将多个卷积核的输出进行拼接。
Inception模块的结构如下图所示:
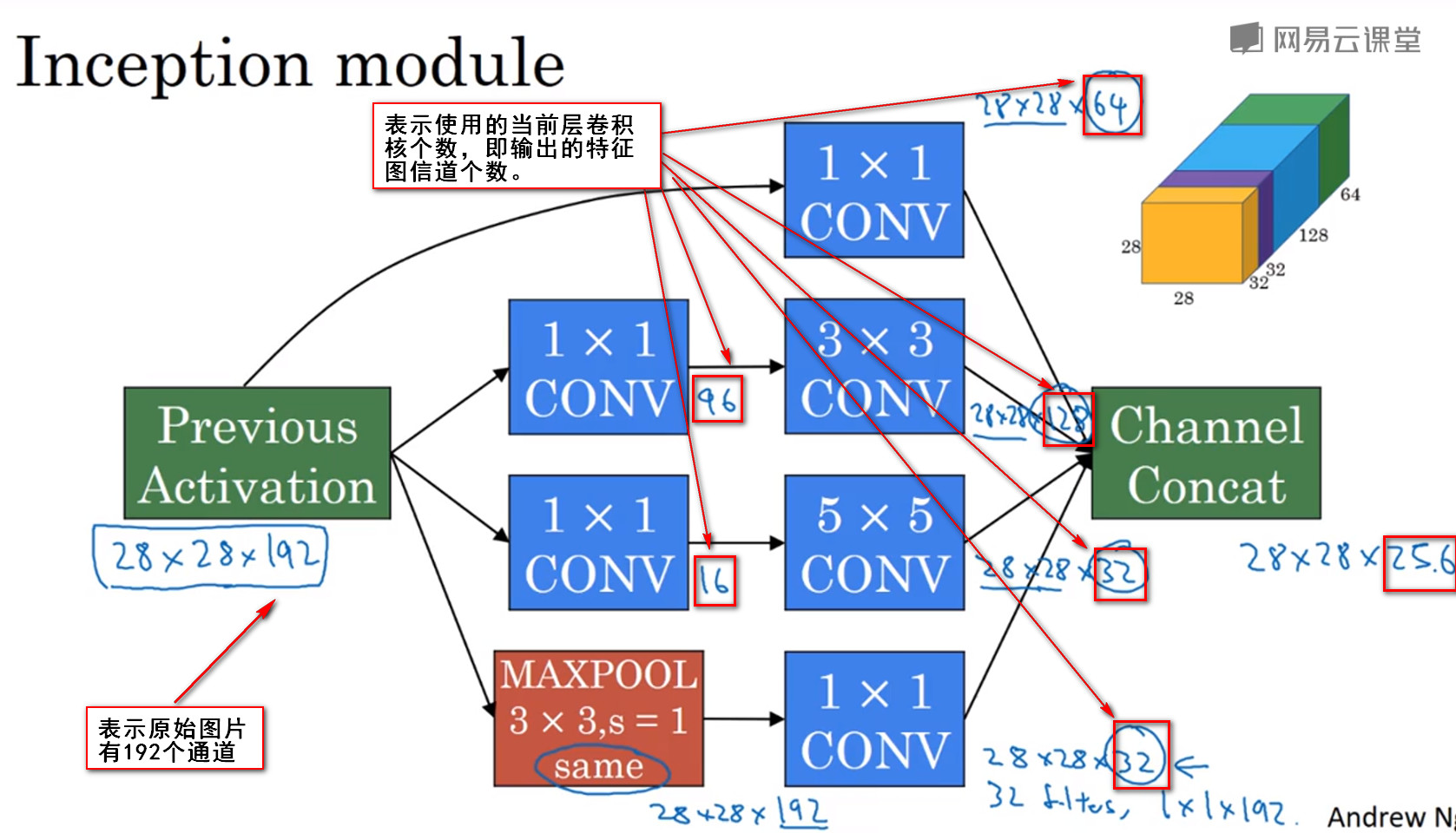
如果不知道使用哪种卷积核(33/55),那么就可以使用Inception模块。
LeNet-5
LeNet-5是一种卷积神经网络,它的原理是使用卷积层和池化层来提取图像的特征,然后使用全连接层来分类。
LeNet-5的结构如下图所示:

AlexNet
AlexNet是一种卷积神经网络,它的原理是使用卷积层和池化层来提取图像的特征,然后使用全连接层来分类。
AlexNet的结构如下图所示:

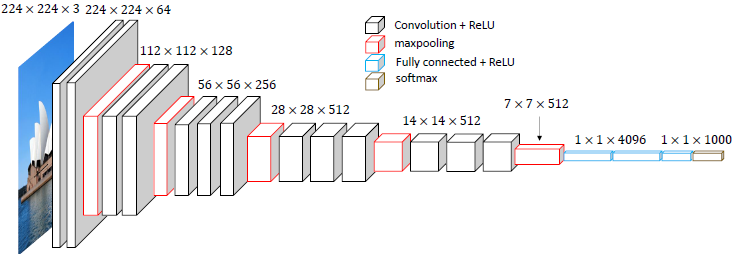
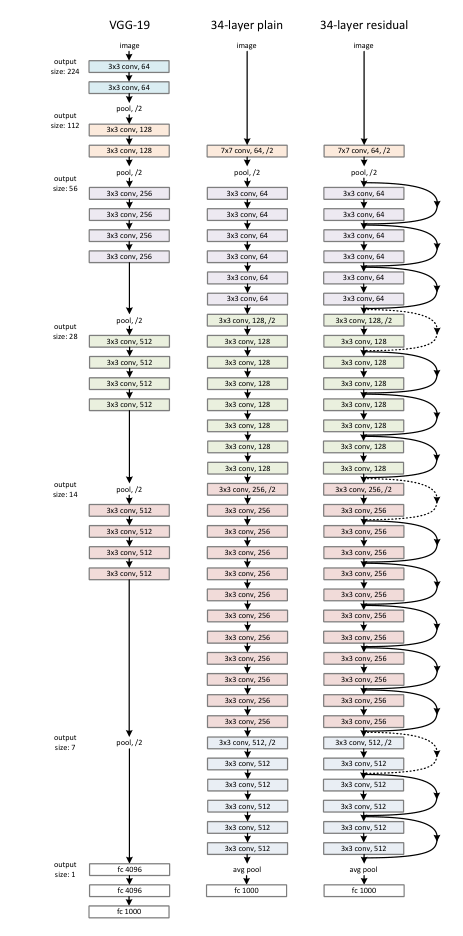
VGG-16
VGG-16是一种卷积神经网络,它的原理是使用卷积层和池化层来提取图像的特征,然后使用全连接层来分类。
VGG-16的结构如下图所示:
ResNet
ResNet是一种卷积神经网络,它的原理是使用残差块来提取图像的特征,然后使用全连接层来分类。
ResNet的结构如下图所示:
残差块
残差块是ResNet中的一个重要概念,它的原理是使用跳跃连接来减少梯度消失,从而加快梯度下降。
残差块的结构如下图所示:
ResNet的作用是减少梯度消失,加快梯度下降。
GoogleNet
GoogleNet是一种卷积神经网络,它的原理是使用Inception模块来提取图像的特征,然后使用全连接层来分类。
GoogleNet的结构如下图所示:
物体检测
目标定位
目标定位是目标检测中的一个重要概念,它的原理是使用边界框来定位目标。目标定位的输入为一张图像,输出包括目标的类别和边界框。
目标点检测
目标点检测是目标检测中的一个重要概念,它的原理是使用目标点来定位目标,确定目标是否存在于图像中。目标点检测的输入为一张图像,输出包括目标的类别和目标点。
Bounding Box
Bounding Box是目标检测中的一个重要概念,它的原理是使用边界框来定位目标。
交并比
交并比是目标检测中的一个重要概念,它的原理是使用交并比来评估边界框的好坏。交并比的公式为:
其中,是交集的面积,是并集的面积。
一般,交并比大于0.5时,就认为边界框是好的。
非极大值抑制(Non-max suppression/NMS)
非极大值抑制是目标检测中的一个重要概念,它的原理是使用交并比来筛选边界框,搜素局部最大值进行选择,抑制非极大值.
- 选择概率最大的边界框,将其输出。
- 将概率最大的边界框与其他边界框进行交并比计算,如果交并比大于阈值,那么就将该边界框删除。
- 重复步骤1和步骤2,直到所有边界框都被处理。
Anchor Box
Anchor Box是目标检测中的一个重要概念,它的原理是使用多个边界框来定位目标,确定目标是否存在于图像中。Anchor Box的输入为一张图像,输出包括目标的类别和边界框。
YOLO
YOLO是一种目标检测算法,它的原理是使用卷积神经网络来定位目标,确定目标是否存在于图像中。非常适合于实时目标检测,端到端的算法,速度快,并且随着yolo的发展,精度也在不断提高。
语义分割:U-Net
U-Net是一种目标检测算法,它的原理是使用卷积神经网络来定位目标,确定目标是否存在于图像中。非常适合于医学图像分割。
转置卷积(Transposed Convolution)
转置卷积是U-Net中的一个重要概念,它的原理是使用转置卷积来将图像的大小变大,从而减少信息的丢失。
![]()
人脸识别
人脸识别是一种目标检测算法,它的原理是使用卷积神经网络来定位目标,确定目标是否存在于图像中,之后使用人脸识别算法来识别人脸。
one-shot learning
one-shot learning是人脸识别中的一个重要概念,它的原理是只使用一张人脸图像来训练,达到能够再次识别这个人的效果。
similarity function的公式为:
如果小于阈值,那么就认为两张图像是同一个人。
Siamese Network
Siamese Network是人脸识别中的一个重要概念,它的原理是使用两个卷积神经网络来提取两张图像的特征,然后使用相似度函数来计算两张图像的相似度。
其中,是卷积神经网络的输出。
Triplet Loss
Triplet Loss是人脸识别中的一个重要概念,它的原理是使用三张图像来训练,其中两张图像是同一个人的图像,另一张图像是另一个人的图像,然后使用相似度函数来计算两张图像的相似度。
其中,是卷积神经网络的输出。
Triplet Loss的公式为:
其中,A是Anchor,P是Positive,N是Negative,是一个常数,一般取0.2。
Triplet Loss的作用是使得Anchor和Positive的相似度大于Anchor和Negative的相似度。
Neural Style Transfer
Neural Style Transfer的原理是将图像的风格转换为另一张图像的风格。(风格迁移)
代价函数
代价函数的公式为:
其中,是内容代价函数,是风格代价函数,是内容权重,是风格权重。
内容代价函数
内容代价函数的公式为:
其中,是内容图像的第l层的激活值,是生成图像的第l层的激活值。
风格代价函数
风格代价函数的公式为:
其中,是第l层的权重,是第l层的风格代价。
第l层的风格代价的公式为:
其中,是风格图像的第l层的Gram矩阵,是生成图像的第l层的Gram矩阵,是第l层的通道数,是第l层的高度和宽度。
第l层的Gram矩阵的公式为:
其中,是第l层的激活值。
Gram矩阵/风格矩阵
Gram矩阵是风格迁移中的一个重要概念,它的原理是使用Gram矩阵来计算风格图像的风格。
Gram矩阵的公式为:
其中,是激活值。
序列模型
- Speech recognition(语音识别)
- Music generation(音乐生成)
- Sentiment classification(情感分类)
- DNA sequence analysis(DNA序列分析)
- Machine translation(机器翻译)
- Video activity recognition(视频活动识别)
- Name entity recognition(命名实体识别)
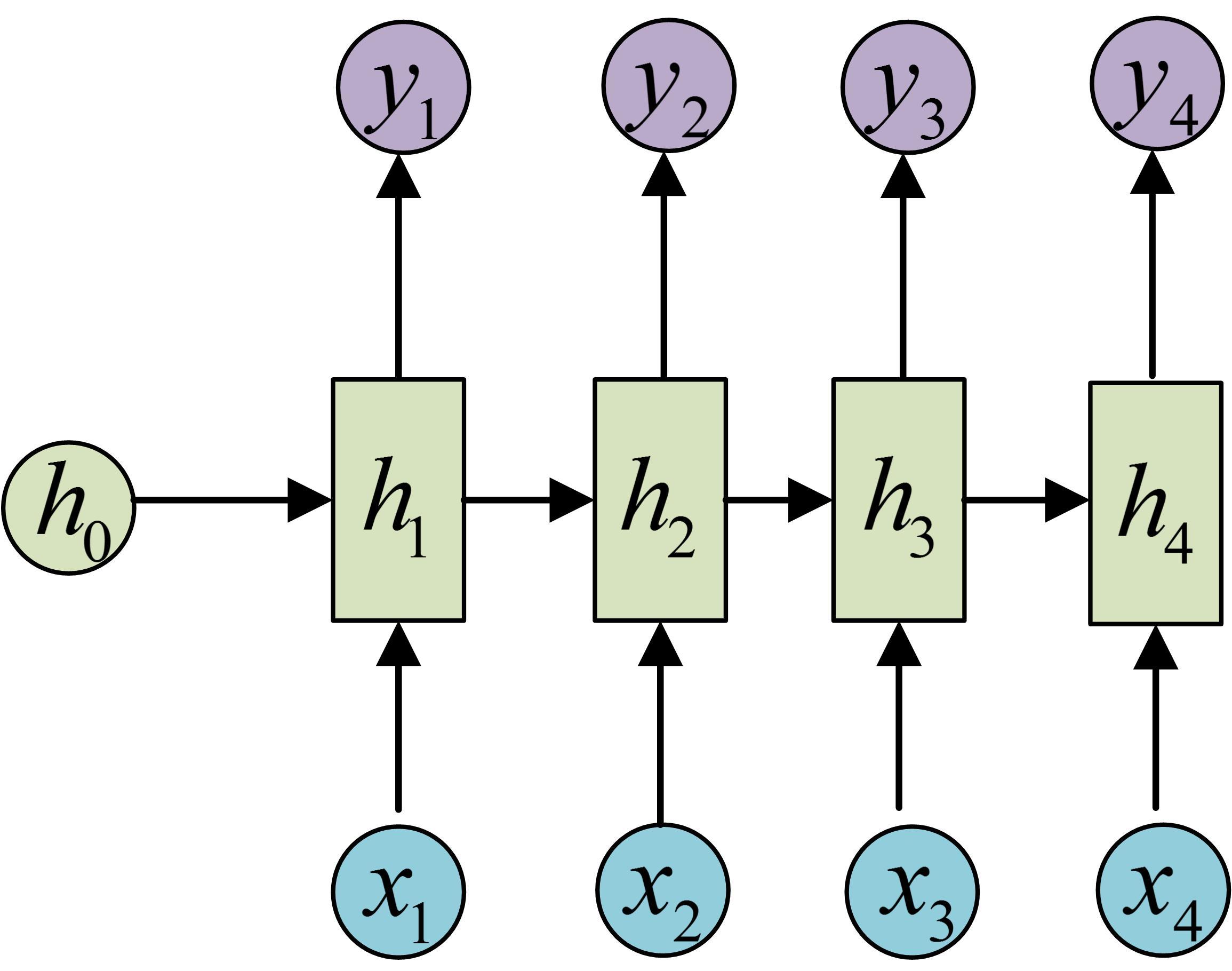
循环神经网络(Recurrent Neural Network/RNN)
循环神经网络是一种序列模型,它的原理是使用循环神经网络来处理序列数据。
循环神经网络的结构如下图所示:
LSTM(Long Short-Term Memory)
NLP
词表特征
词表特征是NLP中的一个重要概念,它的原理是使用词表来表示文本。
词表特征的作用是将文本转换为向量,从而可以使用机器学习算法来处理文本。
词嵌入(Word Embedding)
词嵌入是NLP中的一个重要概念,它的原理是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量
词嵌入矩阵
假设词嵌入向量的长度是300,有10000个单词。词嵌入的过程,其实就算把一个长度为10000的向量映射成长度为300的向量的过程。这个过程可以用一个300*10000的矩阵表示,就是词嵌入向量的数组。每一个词嵌入列向量可以由one-hot编码和计算得到:
学习词嵌入
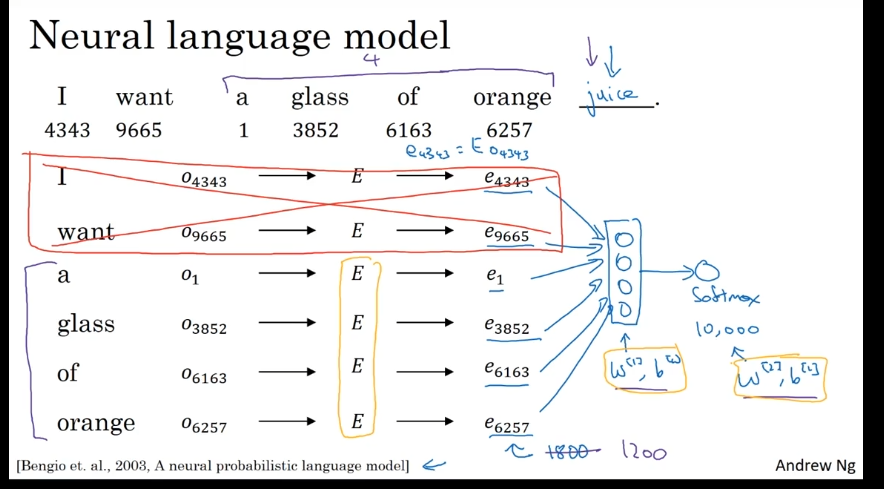
这个任务的输入是一句话中连续的6个单词,输出是第7个单词的预测。在用神经网络建模时,要先根据各个单词的one-hot编码E中选出其嵌入,再把各个单词的嵌入堆叠成一个向量,输入进标准神经网络里,最后用一个预测下一个单词。
word2vec
Word2Vec是一种比语言模型更高效的词嵌入学习算法。与语言模型任务的思想类似,Word2Vec也要完成一个单词预测任务:给定一个上下文(context)单词,要求模型预测一个目标(target)单词。但是,这个目标单词不只是上下文单词的后一个单词,而是上下文单词前后10个单词中任意一个单词。比如在句子"I want a glass of orange juice to go along with my cereal"中,对于上下文单词glass,目标单词可以是juice, glass, my。
具体来说,每一条训练样本是一个上下文单词和目标单词的词对。比如(orange, juice), (orange, glass)。为了生成这些训练数据,我们要从语料库里每一个句子里采样出训练词对。在采样时,要先对上下文单词采样,再对目标单词采样。
负采样
负采样使用的模型和Word2Vec一样简单:输入一个上下文单词的嵌入,经过一个sigmoid层,输出那个上下文单词和某个目标单词是否相关。这样,在每一轮任务中,我们不用去计算多分类的softmax,只要计算一个二分类的sigmoid就行了。
GloVe
GloVe(global vectors for word representation)是一种更加简单的求词嵌入的算法。刚才学习的几种方法都需要进行复杂的采样,而GloVe使用了一种更简洁的学习目标,以代替多分类任务或者二分类任务。为给定上下文单词i时单词j出现的次数。
词嵌入的应用
情感分类
在情感分析任务中,算法的输入是一段文字(比如影评),输出是用户表达出来的喜恶程度(比如1-5星)。
消除歧视
词嵌入会自动从大量的本文中学习知识。但是,数据中的知识可能本身带有偏见。比如,在自动学到的词嵌入看来,男人之于程序员,就像女人之于家庭主妇;父亲之于医生,就像母亲之于护士。类似的歧视不仅存在于性别这一维度,还存在于种族、年龄、贫富等维度。词嵌入本身是向量,歧视其实就是某些本应该对称的向量不太对称了。我们的目的就是在带有偏见的维度上令向量对称。
Sequence to Sequence model
序列到序列模型的输入和输出都是一个序列,比如机器翻译,输入是某一种语言的句子,输出是另一个语言的句子。还有看图说话的例子,输入是一张图片,输出是一句描述图片的话。
由于输出的序列有多种可能,比如把“Jane九月要访问非洲”翻译成英文,可以翻译成"Jane is visiting Africa in September.",也可以翻译成"Jane is going to be visiting Africa in September."。面临多种选择,我们应该怎么挑选最有可能的句子?
我们并没有选择贪心来进行选择,因为贪心算法只会选择当前最优的,而不会考虑后面的选择,并不一定是全局最优。所以我们使用了一种叫做Beam Search的算法。
Beam Search
Beam Search是一种启发式搜算算法。它不能保证求出最优解,却能比贪心算法找出更多更优的解。它会在每一步都保留k个最优的选择,然后在最后一步从中选择最优的那个。

在Beam Search中,我们用了语言模型中求句子的概率的方法,即:
其中,是输出序列的第t个单词,是输入序列,是输出序列的长度。
这个概率是我们的优化目标。但是,使用累乘会碰到计算机硬件精度不够的问题。为此,我们可以把优化目标由累乘取log变成累加:
此外,大多情况下,输出的句子越短,句子可能越不准确。因此,我们可以给优化目标添加一个和长度有关的归一化项:
其中,是一个超参数,一般取0.7。
Beam Search的误差分析
Beam Search是一种启发式算法,它的效果取决于超参数B。一般情况下,为了保证速度,B取10就挺不错了。只有在某些不考虑速度的应用或研究中才会令B=100或更高。
加入Beam Search会让我们调试机器翻译算法时变得更加困难。还是对于开始那个翻译示例,假如人类给出了翻译,算法给出了翻译。对此,我们可以把训练好的RNN当成一个语言模型,输入和,求出这两个句子的概率。如果,那说明RNN的判断是准确的,是Beam Search漏搜了;如果,那说明RNN判断得不准,是RNN出了问题。
Bleu Score
Bleu Score是一种评价机器翻译算法的指标。它的原理是使用n-gram来评价机器翻译算法的输出。
bleu score是一个能十分合理地评价机器翻译句子的指标,后续很多和句子生成相关的任务都使用了此评估指标。我们不用从零开始实现bleu score,可以直接使用很多开源的工具包。
Attention Model(注意力模型)
在注意力模型中,我们先把输入喂给一个BRNN(双向RNN)。这个BRNN不用来输出句子,而是用于提取每一个输入单词的特征。我们会用另一个单向RNN来输出句子。每一个输出单词的RNN会去查看输入特征,看看它需要“关注”哪些输入。
语音识别
语音数据是一维数据,表示每一时刻的声音强度。而我们人脑在在接受声音时,会自动对声音处理,感知到声音的音调(频率)和响度。
语音识别任务的输入是语音数据,输出是一个句子。我们可以直接用注意力模型解决这个问题(令输出元素为字母而不是单词),也可以用一种叫做CTC(connectionist temporal classification)的算法解决。
触发字检测
触发词检测也是一类常见的语音问题,我们可以用序列模型轻松解决它。
触发词检测在生活中比较常见,比如苹果设备的"Hey Siri"就可以唤醒苹果语音助手。我们的任务,就是给定一段语音序列,输出何时有人说出了某个触发词。
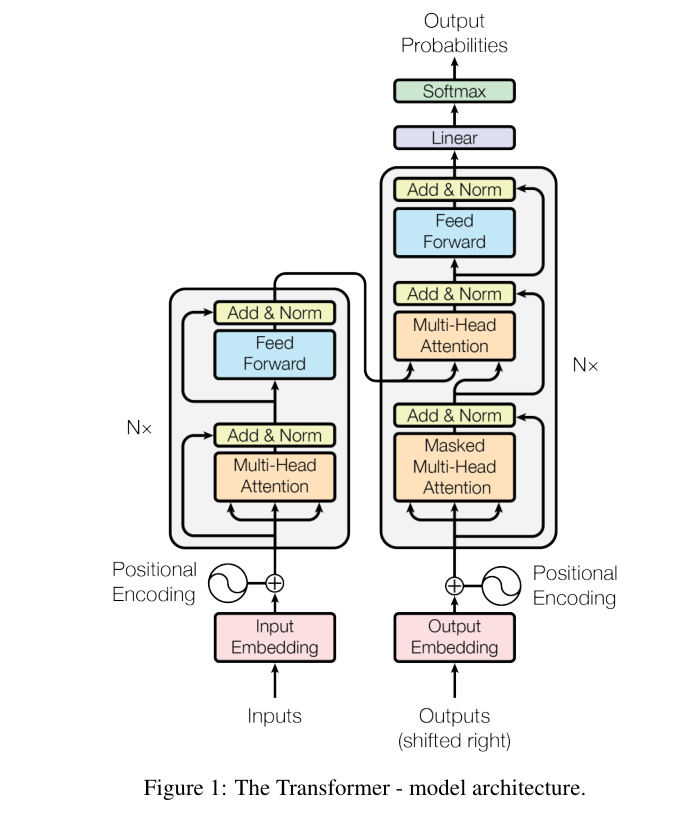
Transformer
Transformer是深度学习发展史上的一次重大突破,它在多个领域中取得了傲人的成绩。Transformer最早用于解决NLP任务,它在CV任务上的潜力也在近几年里被挖掘出来。
自注意力
Transformer会为序列里的每一个元素用注意力生成一个新的表示,就和CNN里卷积层能为每个像素生成高维特征向量一样。这个表示和词嵌入不同,词嵌入只能表示一个单词本身的意义,而「自注意力」生成的表示是和句子里其他单词相关的。
多头注意力
多头注意力表示多次利用自注意力机制,生成多个表示,就和CNN里N个卷积核能生成N个特征一样。
Transformer的网络架构