
语言模型
神经网络语言模型
用神经网络的方法来训练语言模型,解决语言模型的两个问题。
语言模型的两个问题:
- P(“后藤一里更大”)和P(“后藤二里更大”)哪个概率更大。
- 后藤一里的外号是____。这个空格应该填什么?
独热编码(one-hot encoding)
独热编码就是用一个向量来表示一个词,这个向量的维度是词典的大小,向量值为1的位置是词在词典中的索引,其余的位置都是0。这样的向量表示方法是稀疏的,因为大部分维度都是0。假设词典的维度为8,则独热编码为下图所示:
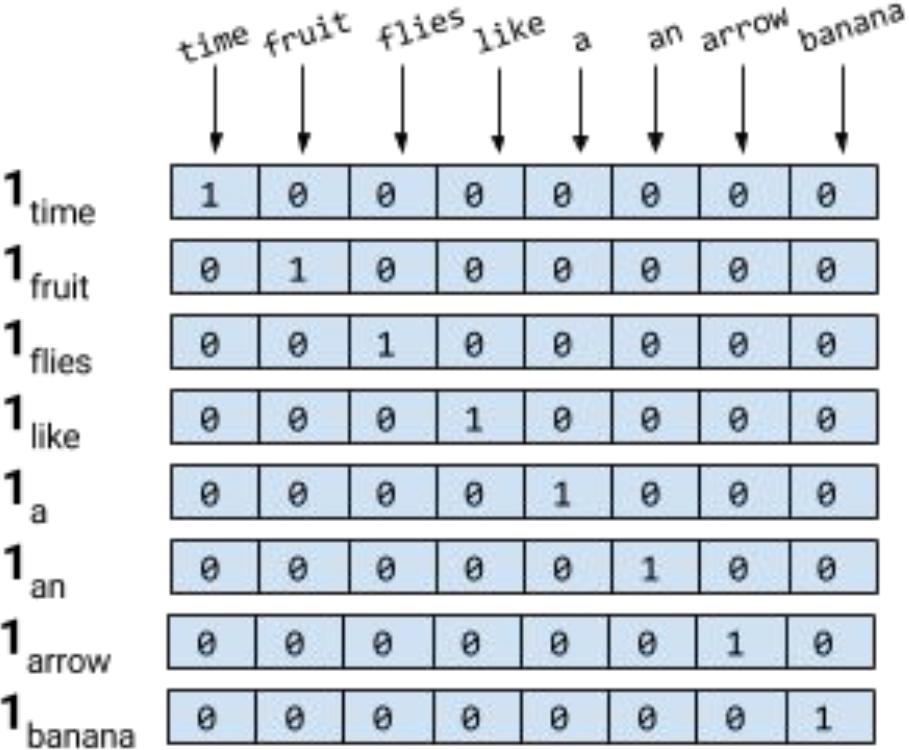
从上图可以得知,独热编码占用的内存空间大,而且向量之间的相似度(向量之间的距离、夹角等)无法计算(每个向量的相似度都一样)。因此,独热编码不适合用于神经网络的输入。
Word Embedding
有没有一种好的方法来表示词呢?答案是有的,那就是词向量。我们可以将独热编码乘以一个向量Q,得到一个新的向量,这个向量就是词向量。这种方法叫做Word Embedding。将文字转换成向量,这样就可以用向量来表示词。
假设一个词的独热编码为,我们可以乘以一个矩阵,这个矩阵维度是,得到一个新的向量,这个向量就是词向量。这样,这个词的维度就从5降到了3,而且向量之间的相似度可以计算了。
Word2Vec
Word2Vec是一种用于生成词向量/做Word Embedding的模型,它有两种模型:CBOW和Skip-gram。CBOW是根据上下文预测中心词,Skip-gram是根据中心词预测上下文。Word2Vec的模型结构如下图所示:

通过Word2Vec模型的训练,我们可以得到一个词向量矩阵,这个矩阵的维度是,是词典的大小,是词向量的维度。Word2Vec模型的主要作用不是为了准确地预测词,而是为了得到词向量矩阵。
Word2Vec模型其实是一种预训练模型,可以使用迁移学习,得到预训练好的Q矩阵,然后在自己的数据集上进行使用,可以采取冻结(不改变Q矩阵),也可以采取微调(随着任务的改变,改变Q矩阵)。
但是Word2Vec模型也有缺点,就是不能表示多义词。比如“苹果”这个词,它有两个意思:一是水果,二是公司。Word2Vec模型只能得到一个词向量,无法区分这两个意思。因此,Word2Vec模型的词向量是不够准确的。
ELMo
考虑到Word2Vec模型的缺点,我们提出了ELMo模型,ELMo也是一种用于生成词向量/做Word Embedding的模型,它是一种双层双向LSTM模型。ELMo模型的结构如下图所示:

ELMo也是一种预训练模型,可以使用迁移学习。ELMo是专门做生成词向量,得到Q矩阵的,并且不只是训练得到Q矩阵,还会把上下文信息融入到Q矩阵中。上图中左边的LSTM是正向LSTM,用于获取上文信息,右边的LSTM是反向LSTM,用于获取下文信息。
Word2Vec模型的缺点就是该模型不含有任何上下文信息,而ELMo模型包含了上下文信息。因此,ELMo模型的词向量是更加准确的,可以通过上下文的信息解决多义词的情况。
