
集成学习
概念
集成学习归属于机器学习,他是一种训练思路,并不是某种具体的方法或者算法。集成学习的思想是将多个学习器(也称为基学习器)结合在一起,以提高整体性能的一种方法。集成学习的原理是通过结合多个学习器的预测结果,来获得比单个学习器更强大、更鲁棒的模型。
常见方法
Voting
Hard Voting
多个学习器投票给出最终的预测结果,以获得最高投票的类别作为最终输出。
Soft Voting
学习器给出概率估计,最终的预测结果是所有学习器概率的平均或加权平均。
Bagging
在数据集上独立、并行的训练n个模型,如果是回归问题,那么最终的预测结果是这n个模型预测结果的平均值;如果是分类问题,那么最终的预测结果是这n个模型预测结果中最多的那个类别。主要作用是减少过拟合,提高泛化能力。
随机森林就是一种基于Bagging的方法,使用决策树作为基学习器。
每个模型是在基于bootstrap sampling的数据集上进行训练的,bootstrap sampling就是从原始数据集中有放回的抽取n个样本(采样一个放回一个采样一个放回一个),作为新的数据集(大概的数据集可以采样得到)。这样每个模型的训练数据集都是不同的,这样可以增加模型的多样性,进而提高模型的泛化能力。
Boosting
在一个学习器训练的过程中,根据前一个学习器的性能来调整样本权重,使得之前被错误分类的样本在后续模型中得到更多关注。Boosting的思想就是将多个弱一点的模型结合在一起,形成一个强大的模型,主要目的是降低偏差。常见的提升算法包括AdaBoost、Gradient Boosting和XGBoost。
Boosting是按顺序学习n个模型,在第i步训练第i个模型时,计算评估该模型的误差,然后根据这个误差对数据集进行重新采样,让误差大的样本在后一个模型中得到更多关注。重复该操作,最终的预测结果是所有模型预测结果的加权平均。
Stacking(刷榜)
将多个不同的学习器的预测结果作为输入,训练一个元学习器来融合这些结果。这个元学习器能够捕捉到不同基学习器的优势,提高整体性能。
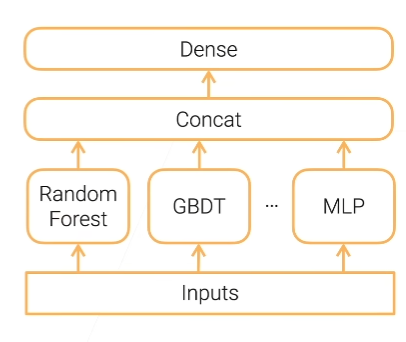
以下是Stacking的主要步骤:
- 准备训练数据集:
将原始的训练数据集分为两部分,一部分用于训练基学习器,另一部分用于训练元学习器。 - 训练基学习器:
使用第一部分的数据集,分别训练多个不同类型的基学习器。这些基学习器可以是任何类型的模型,例如决策树、支持向量机、随机森林等。每个基学习器产生一个独立的预测结果。 - 生成第一层的预测结果:
使用第二部分的数据集,对每个基学习器进行预测。这些基学习器的预测结果构成了新的训练集,被用于训练元学习器。 - 训练元学习器:
使用新的训练集,元学习器学习如何结合基学习器的预测结果。元学习器的目标是最小化整体模型的预测误差。元学习器可以是简单的线性模型,也可以是更复杂的模型,具体取决于问题的性质。 - 生成最终预测:
当需要对新的数据进行预测时,首先使用已训练好的基学习器生成各自的预测结果,然后将这些结果输入到元学习器中,最终得到整体模型的预测输出。
为了降低偏差bias,可以使用multi-layer Stacking,即在第一层的基学习器之上再加一层基学习器,然后再加一层元学习器。这样可以进一步提高模型的性能,但是也会增加计算开销。
为了降低方差variance,减少过拟合,可以使用k折交叉验证。首先,将训练数据集分为k个子集,然后每一轮使用k-1个折训练基学习器,使用1个折生成预测结果,重复k轮,每次选择不同的折作为测试集。这样,每个折都有机会充当测试集,而模型在整个数据集上都有机会被评估。最终得到k个基学习器的预测结果。这样可以减少由于随机划分而引入的方差,提供对模型性能更稳健的估计。
Ensemble of Deep Learning Models
深度集成学习,在深度学习领域,也可以使用集成学习的思想。例如,将多个神经网络的预测结果结合,或者通过训练多个不同结构的神经网络并集成它们的输出来提高性能。
总结
| Reduce | Bias | Variance | Computation Cost | Parallelization |
|---|---|---|---|---|
| Bagging | Y | n | n | |
| Boosting | Y | n | 1 | |
| Stacking | Y | n | n | |
| K-fold multi-layer Stacking | Y | Y | n * l * k | n*k |
l为多层stacking的层数,k为折数,n为基学习器个数。
集成学习通常能够在各种情况下提高模型的性能,降低过拟合风险,并提高模型的鲁棒性。然而,需要注意的是,集成学习可能增加了模型的复杂性和计算开销。
