
对比学习
对比学习
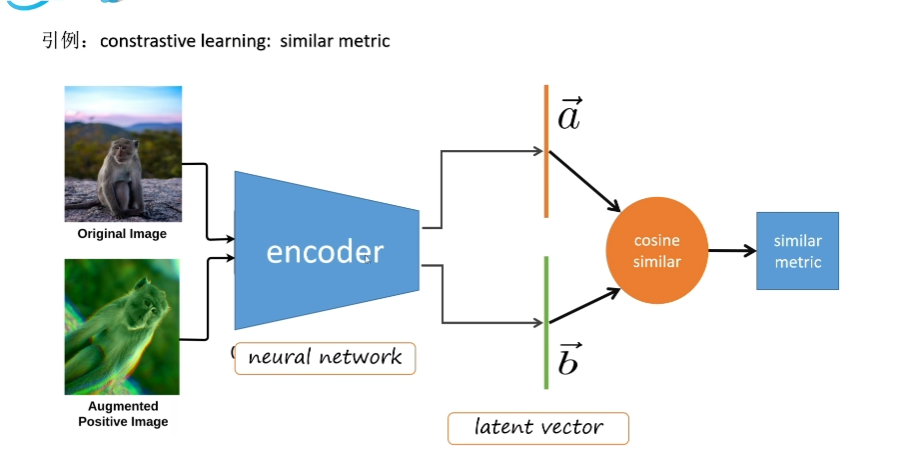
对比学习是一种自监督学习方法,它的目标是学习数据的表示,使得相似的样本在表示空间中更加接近,而不相似的样本在表示空间中更加远离。对比学习的核心思想是通过最大化相似样本的相似性,最小化不相似样本的相似性,来学习数据的表示。
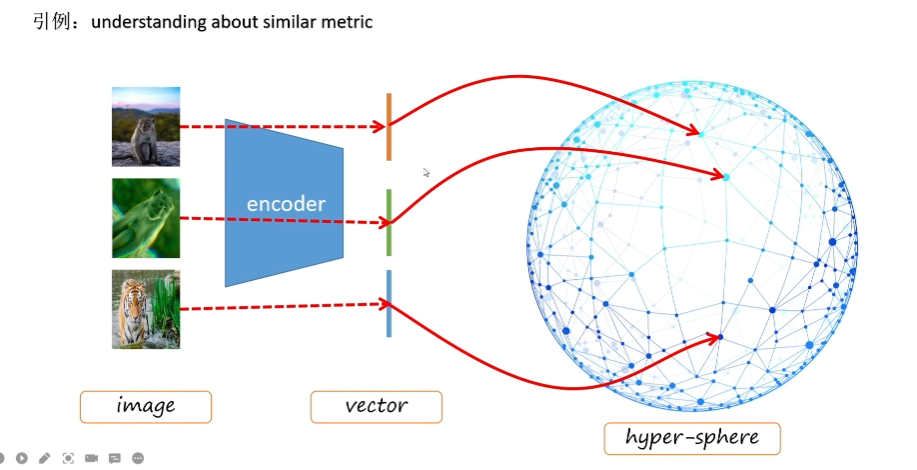
例如,在一个新的环境中,有两只猫和一只狗,此时你并不认识猫和狗,即并没有猫与狗的标签。但是你会发现,相比于狗来说,两只猫之间的相似度更高。即在你不理解标签情况下,通过对比的方式得知两只猫更相似,例如我们下意识发现两只猫的耳朵都是竖着的,而狗的耳朵是下垂的;或者我们可以发现狗身上没有斑纹而猫身上的斑纹比较多。通过对比的方式让我们可以在更高级的特征方面理解图像 (High-level features),例如在原本的有监督任务中,我们仅仅是通过大规模样本的数据训练一个表征的模型,这个模型只关注于在样本下猫的特征,而缺少了关注类之间不同的高级特征。
为什么我们需要对比学习?或者说需要无监督、自监督或半监督学习?绝大多数情况下,例如人脸数据集,或者医学影像数据集,这些数据集都是大规模的数据集,我们往往无法,或者没有精力、代价去将全部的数据集都作标注。通过网络爬虫等手段我们可以很快的采集相当数量的人脸数据集,然而将相当数量的图片做上标注在时间上是困难的;医学影像数据往往需要专业人士花费无数的时间来手动进行分类,分割。因此我们可以通过对比学习,在数据仅有一部分标注的情况下,依然能使模型学习到相当好的效果。
Triplet Loss
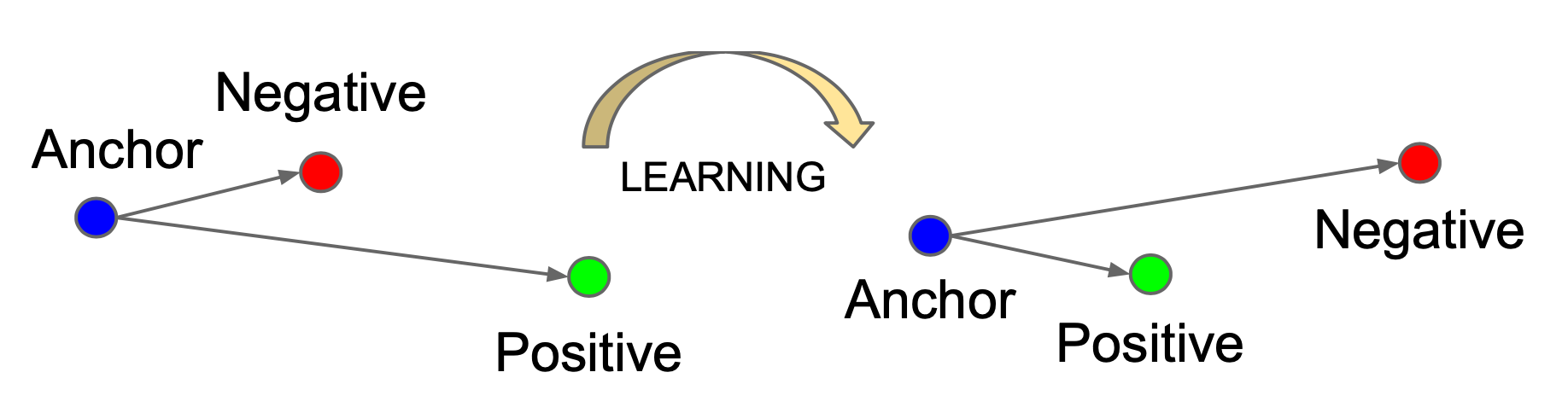
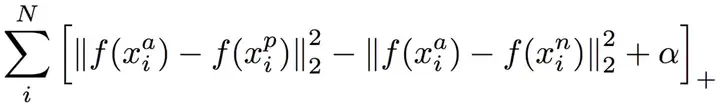
给定一个锚输入,选择一个正样本和负样本。我们希望锚输入和正样本之间的距离尽可能小,锚输入和负样本之间的距离尽可能大。距离的远近代表了样本之间的相似度。距离越近,相似度越高;距离越远,相似度越低。
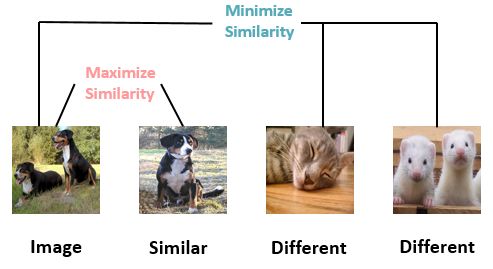
对比模型的损失函数
对比学习的常见的损失函数有:Triplet Loss、Contrastive Loss、N-pair Loss、InfoNCE Loss等。对比模型的损失函数的核心思想是通过最大化相似样本的相似性,最小化不相似样本的相似性,来学习数据的表示。常用输入在隐空间内投影的距离/夹角表示相似度。
以下式子可以用来构建相似度:

使用相似度来构建对比损失函数:




对比学习框架
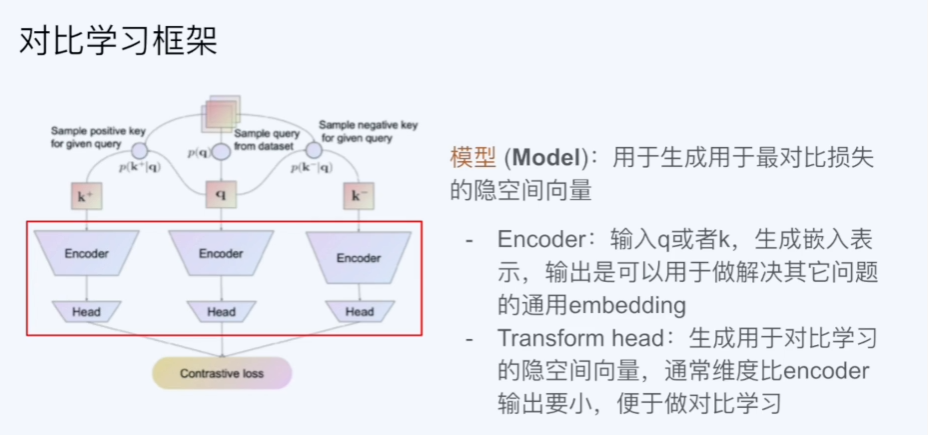
对比学习将正样本的输入作为query,其他样本(用于对比的数据)的输入作为key,通过一个对比模型计算query和key的相似度。根据相似度来计算对比损失函数,然后梯度下降进行优化。由于用于对比的数据key最好是从一个encoder中得到的(保持key的一致性),但是在实际应用中,由于key的数量很大,我们往往会使用mini-batch进行训练,在这个训练过程中,encoder中的参数会进行更新,这就导致encoder发生了变化。该问题的解决方法是动量更新,将参数的更新公式变为:,即在每次更新参数时,根据的大小,来决定更新的幅度。这样可以使得encoder的参数在训练过程中保持稳定。详细参看Momentum Contrast for Unsupervised Visual Representation Learning
对比学习的论文tricks
SwAV:multi crop
MoCo:momentum encoder
SimCLR:data augmentation、MLP projection head
BYOL:no negative sample,MLP prediction head/predictor
SimSiam:no negative sample,no momentum encoder
对比学习被vision transformer给掩盖了,现在主流的是MAE,但是对比学习的思想是非常重要的,对比学习的思想是可以用在其他领域的。
