Transformer
Transformer正在席卷NLP领域,打破多项NLP记录,推动技术的最前沿,被应用于机器语言翻译、会话聊天机器人,甚至是更强大的搜索引擎。现在,深度学习领域热衷于Transformer。
Self-attention机制
前言:输入是一系列的向量
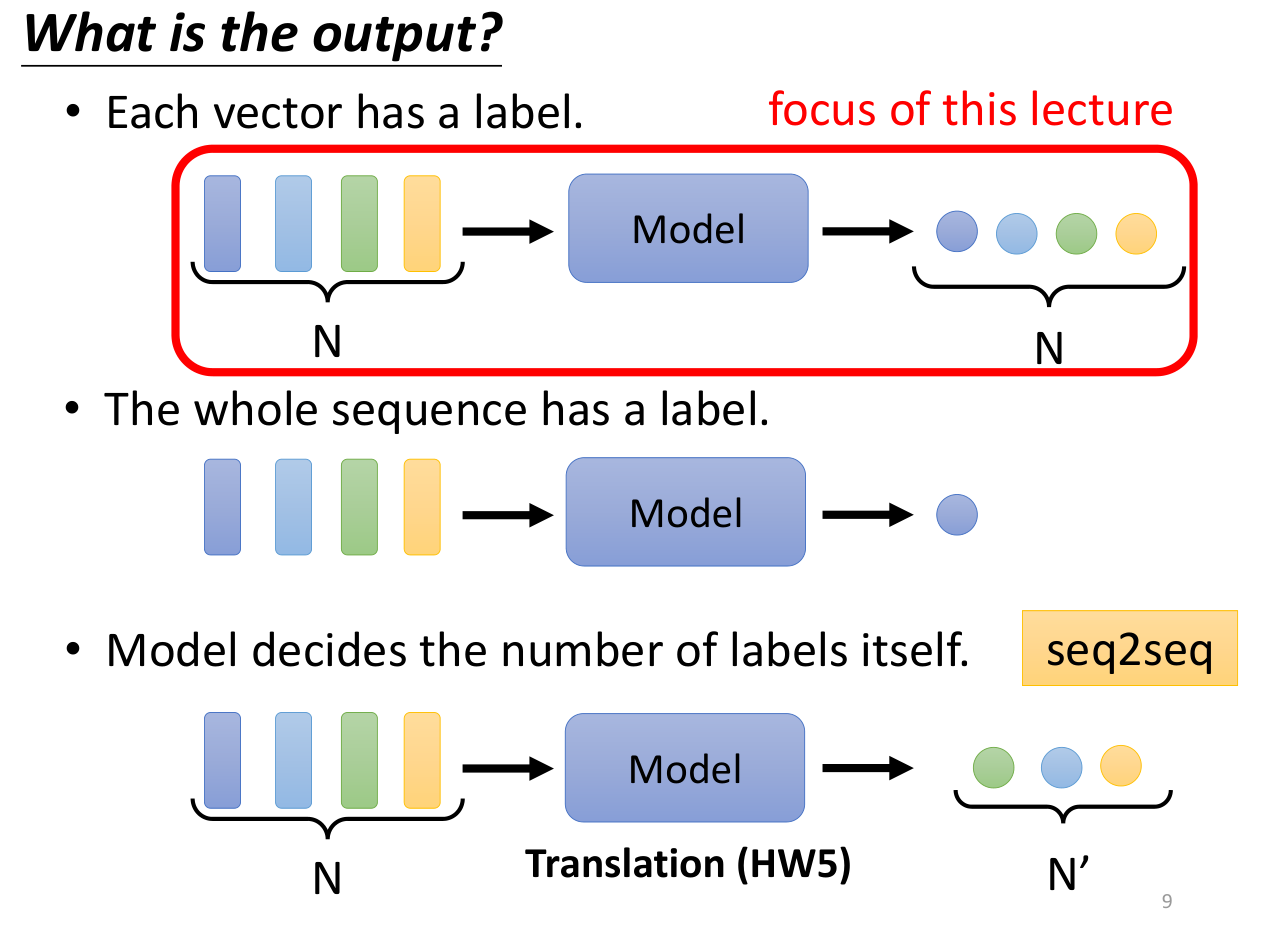
- 输入是N个向量,对应N个输出,例如句子的词性标注
- 输入是N个向量,对应一个输出,例如句子情感分析
- 输入是N个向量,对应N’个输出(seq2seq),例如机器翻译
自注意力机制
N个输入->N个输出
自注意力机制:把焦点聚焦在比较重要的事物上,而不是把注意力平均分配给所有事物。
![]()
![]()
每个输入都会与其他输入进行交互,得到一个输出,但是也不是其他全部输入都会产生一定影响,而是该输入相关度较高的输入才会产生。怎么衡量相关度呢?就是通过自注意力机制。
![]()
有两种方式可以计算相关度,我们采取点积的形式。
![]()
![]()
我们使用(查询),去与每个进行点积,获得相似度,之后使用soft-max函数,得到概率,soft-max也可以换成其他函数。
使用soft-max求概率时会有一个问题,就是如果值的分布相差很大,在数量级较大的情况下,那么soft-max会将概率都分配给最大值对应的标签,这样就会导致梯度消失。因此,我们可以采取一些方法来解决这个问题,比如使用缩放的方法,将点积的结果除以,其中是的维度然后再输入到soft-max。这样就可以避免梯度消失的问题。
![]()

然后使用(值)乘以概率,这样就可以知道哪些内容重要,哪些内容不重要了,最终得到输出。经过推导之后,我们可以采取矩阵的形式进行计算。
![]()
![]()
![]()
综上,我们可以得到下面的式子
![]()
自注意力机制属于注意力机制(Q,K,V),但自注意力机制在注意力机制的基础上规定了都来源于,唯一需要学习的参数就是、、。
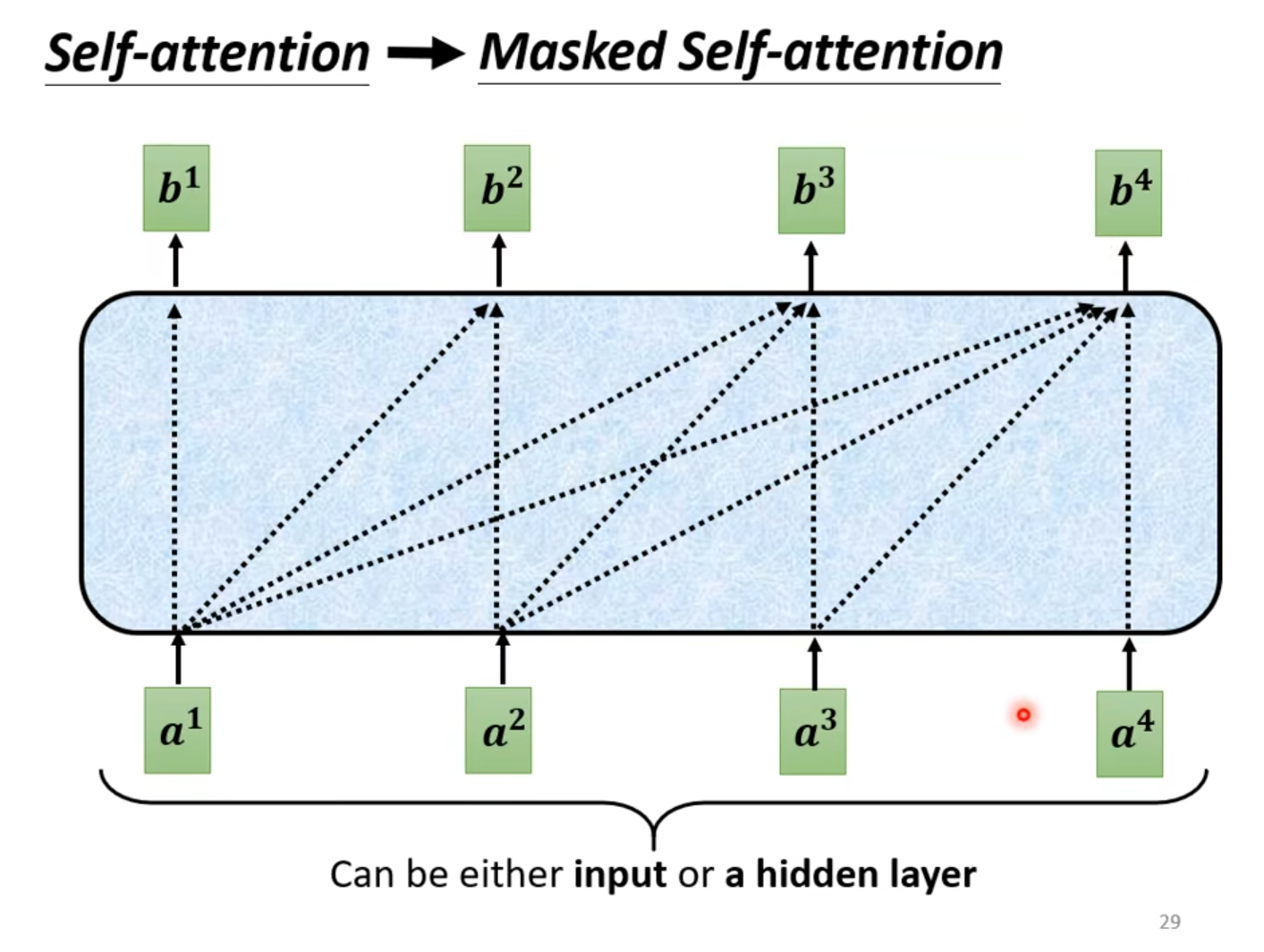
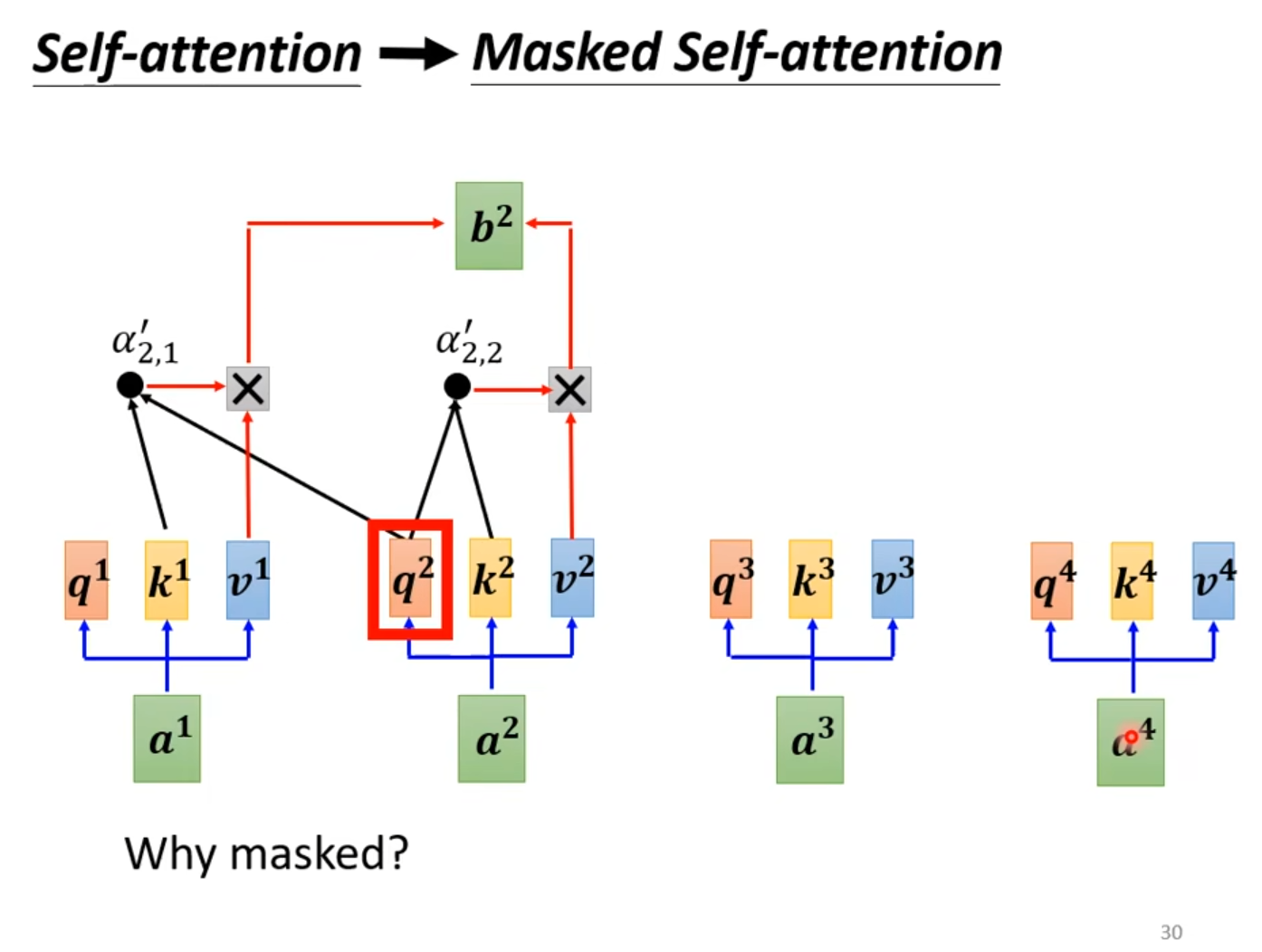
Masked self-attention
Masked self-attention是指只能看到当前时刻之前的词,不能看到当前时刻之后的词。如下图所示

比如生成语言模型,生成I have a dream时,只能看到I have a,不能看到dream。

首先,一开始只有I,然后I与I自己做Attention,并不是与所有词进行Attention计算,然后得到have,再将I与have做Attention,得到a,再将I、have与a做Attention,得到dream,再将I、have、a与dream做Attention,得到终止符EOF。
Multi-head self-attention
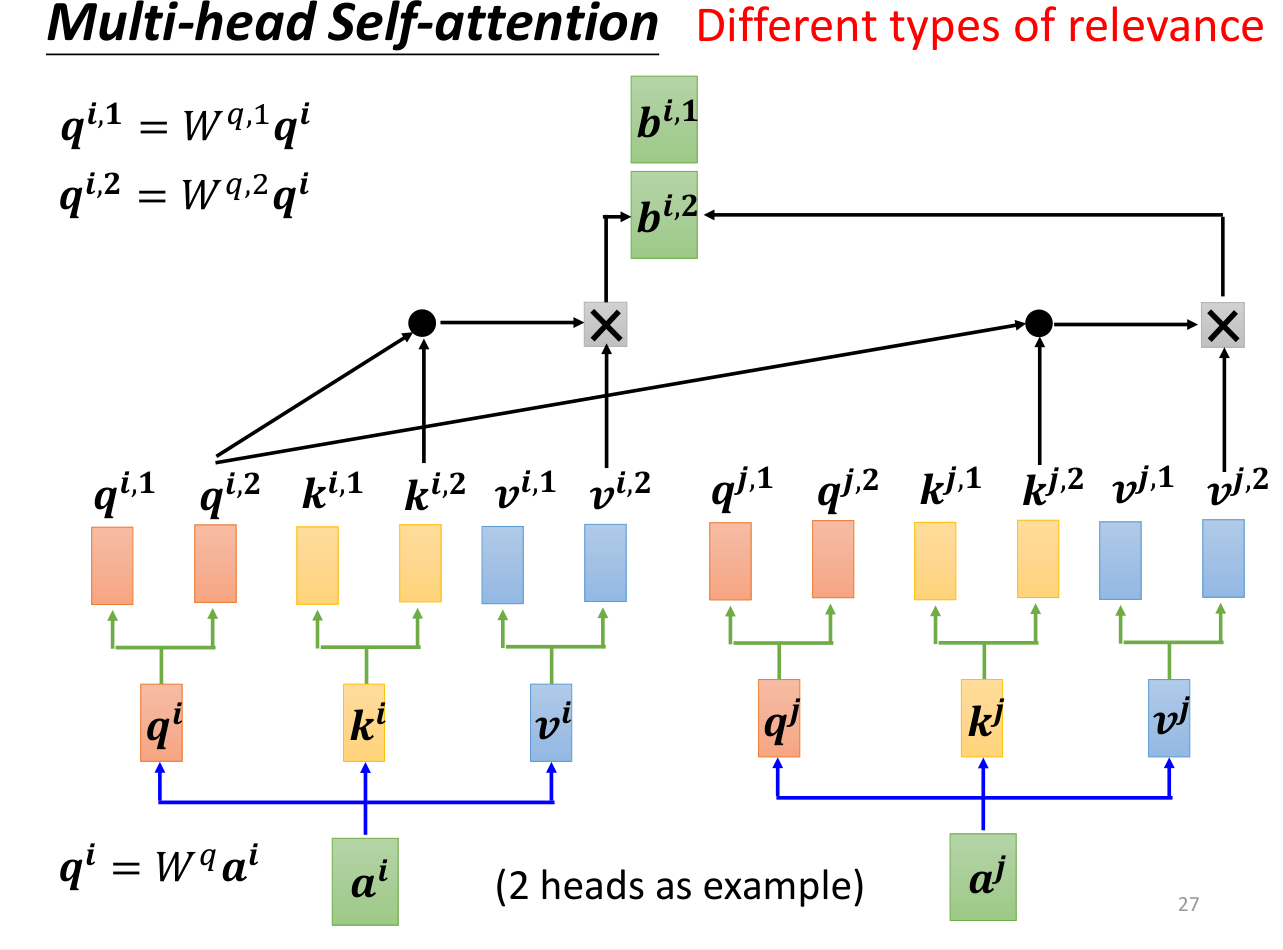
计算和单头自注意力差不多,只不过只和、进行计算,只和、进行计算,得到、。
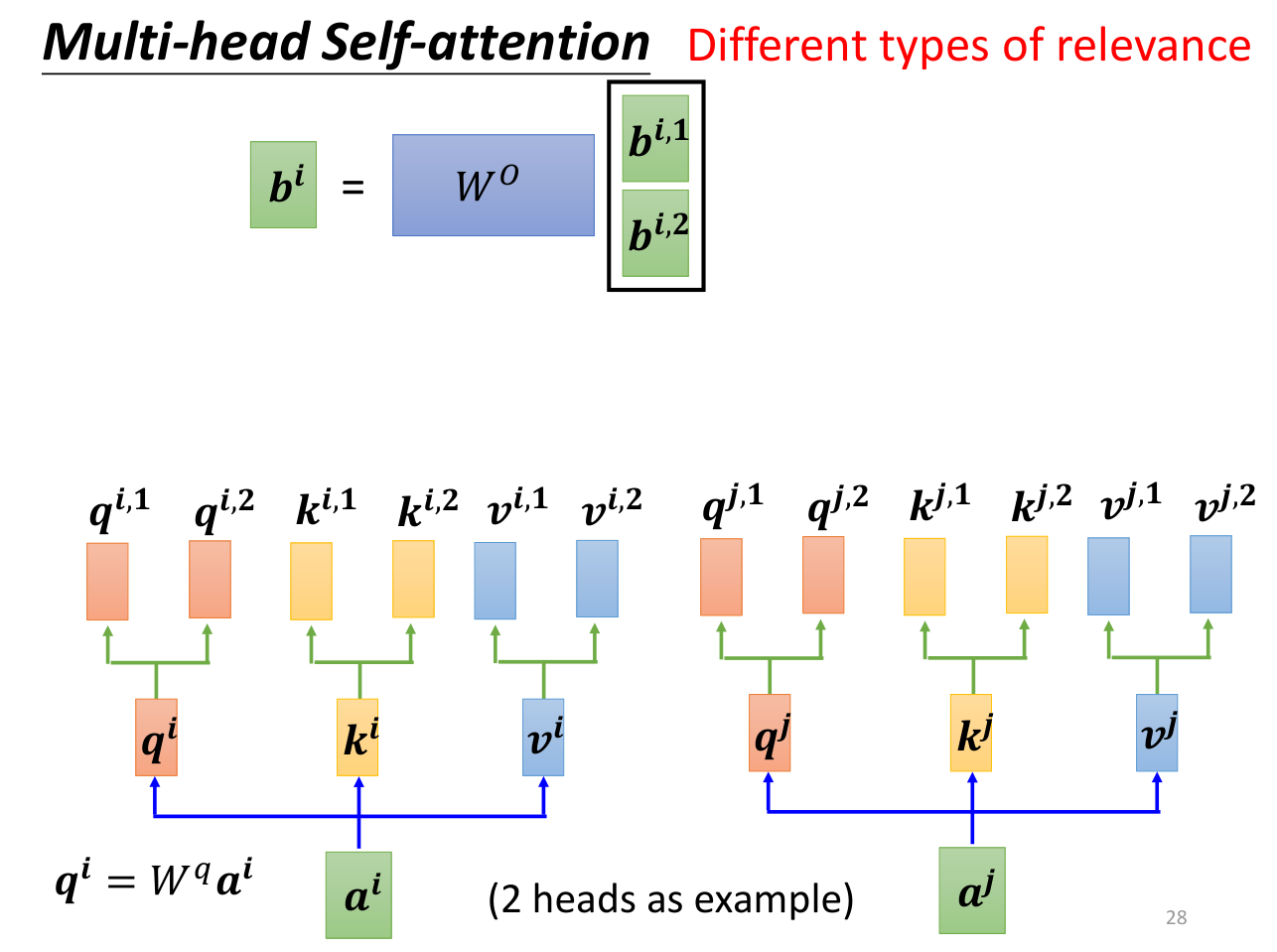
得到、之后,将其拼接起来,乘以矩阵得到。
多头注意力机制流程图如下
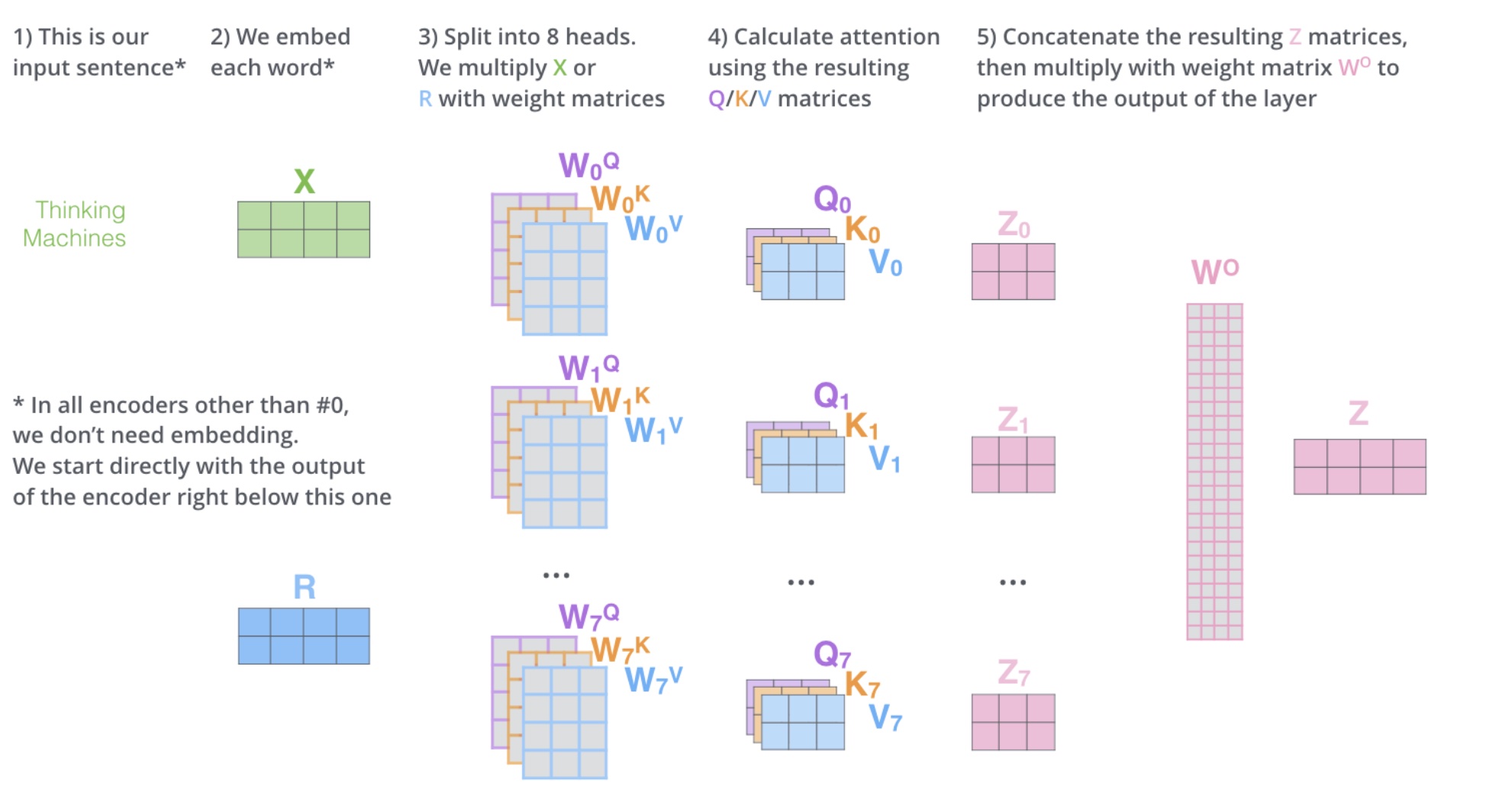
多头自注意力机制的优势在于可以学习到不同的注意力,不同的注意力可以学习到不同的特征,这样就可以得到更好的结果。
自注意力的缺陷
自注意力机制是有缺陷的,因为自注意力机制是并行计算的,也就是说词与词之间不存在顺序关系。所以我们需要引入位置编码。
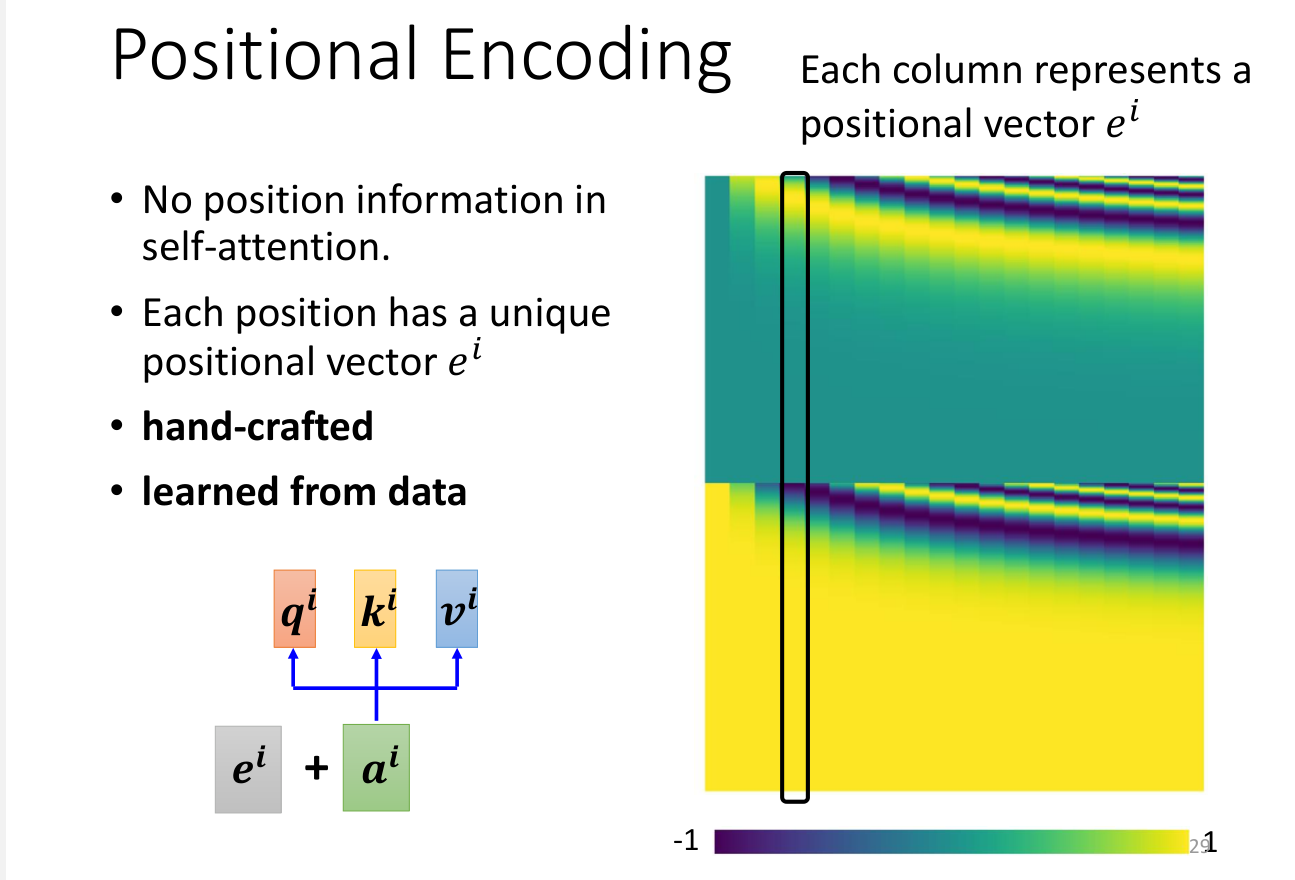
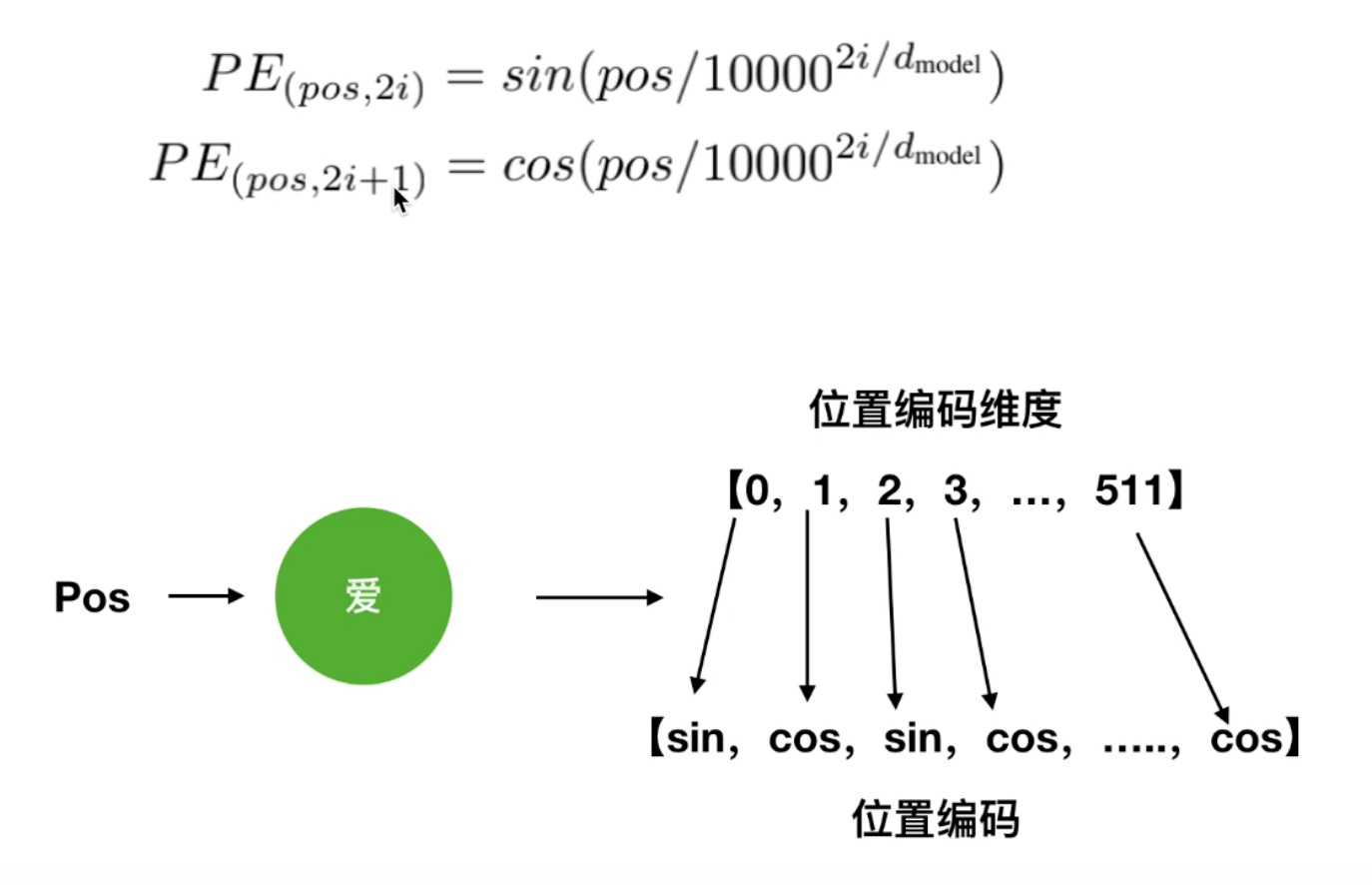
其中pos是词的位置,d是词的维度,是偶数位置的位置编码,用sin函数,是奇数位置的位置编码,用cos函数。

关于position encoding的更多知识,可以参考Learning to Encode Position for Transformer with Continuous Dynamical Model
此外,自注意力的计算量也是很大的,未来的研究方向可能会集中在如何减少计算量。
Transformer
Transformer实际就是seq2seq的一个特例。seq2seq可以应用在Speech Recognition、Machine Translation、Speech Translation等,seq2seq的核心就是encoder-decoder结构,transformer的核心也是encoder-decoder结构。
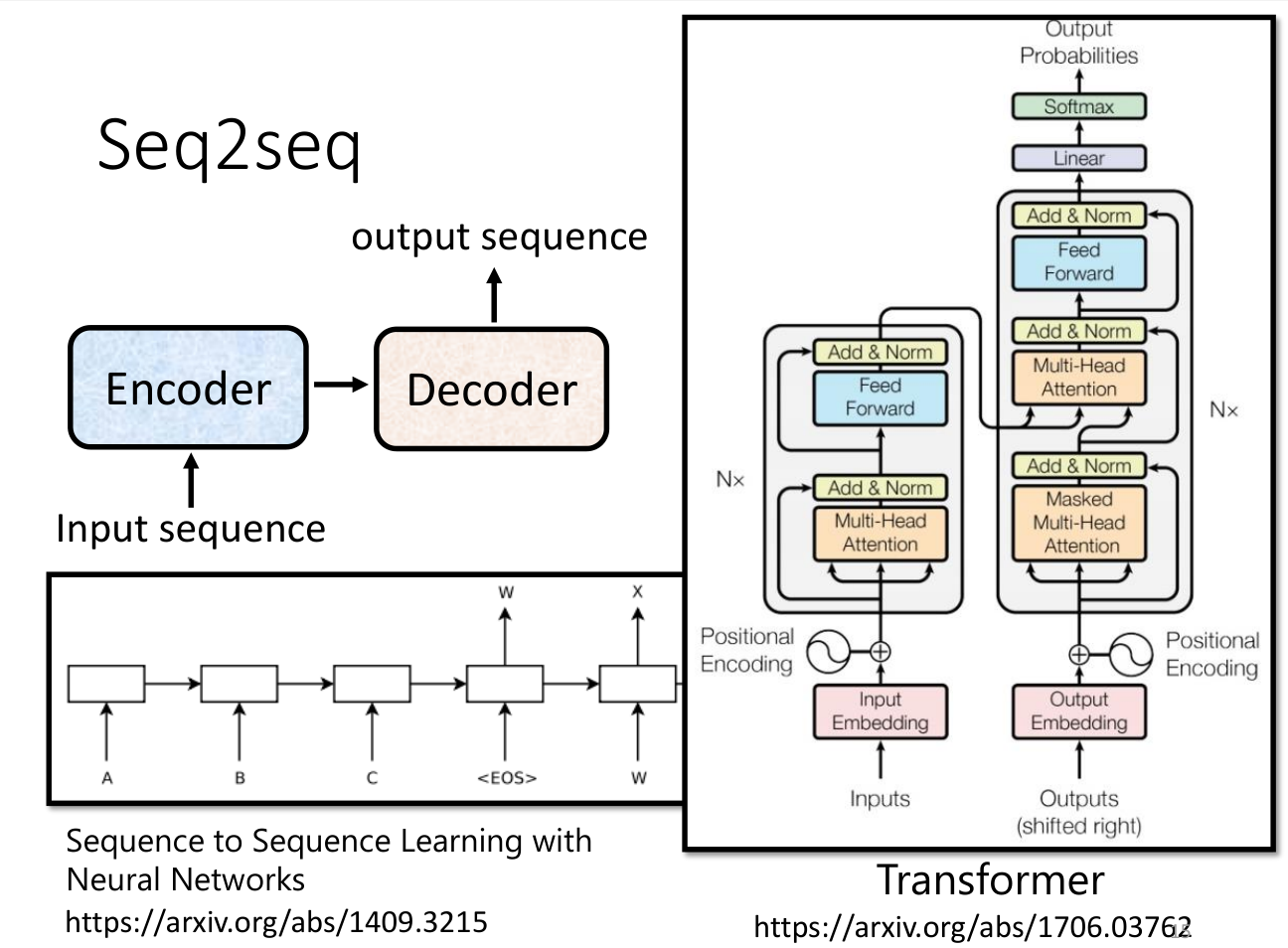
Transformer的encoder部分是多头自注意力机制。
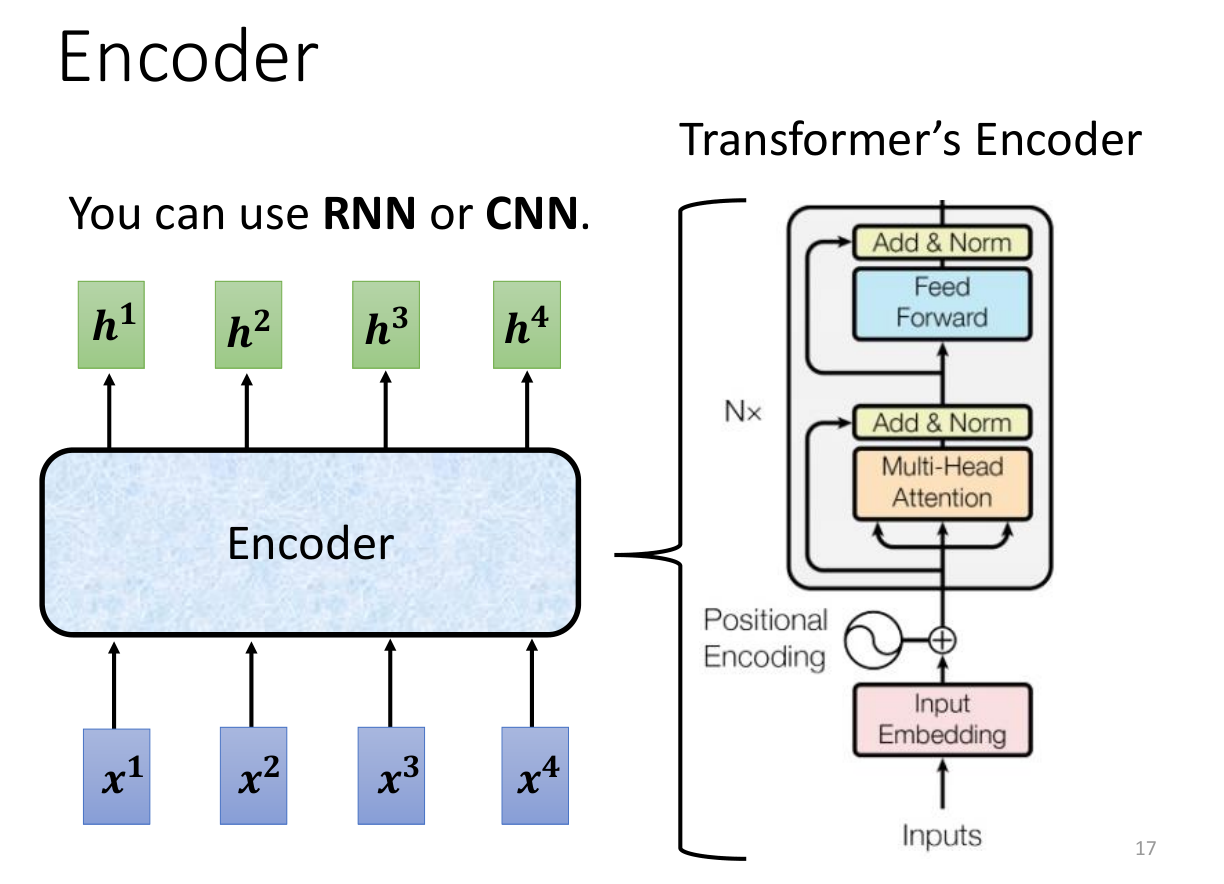
Encoder
Encoder部分的详细结构如下
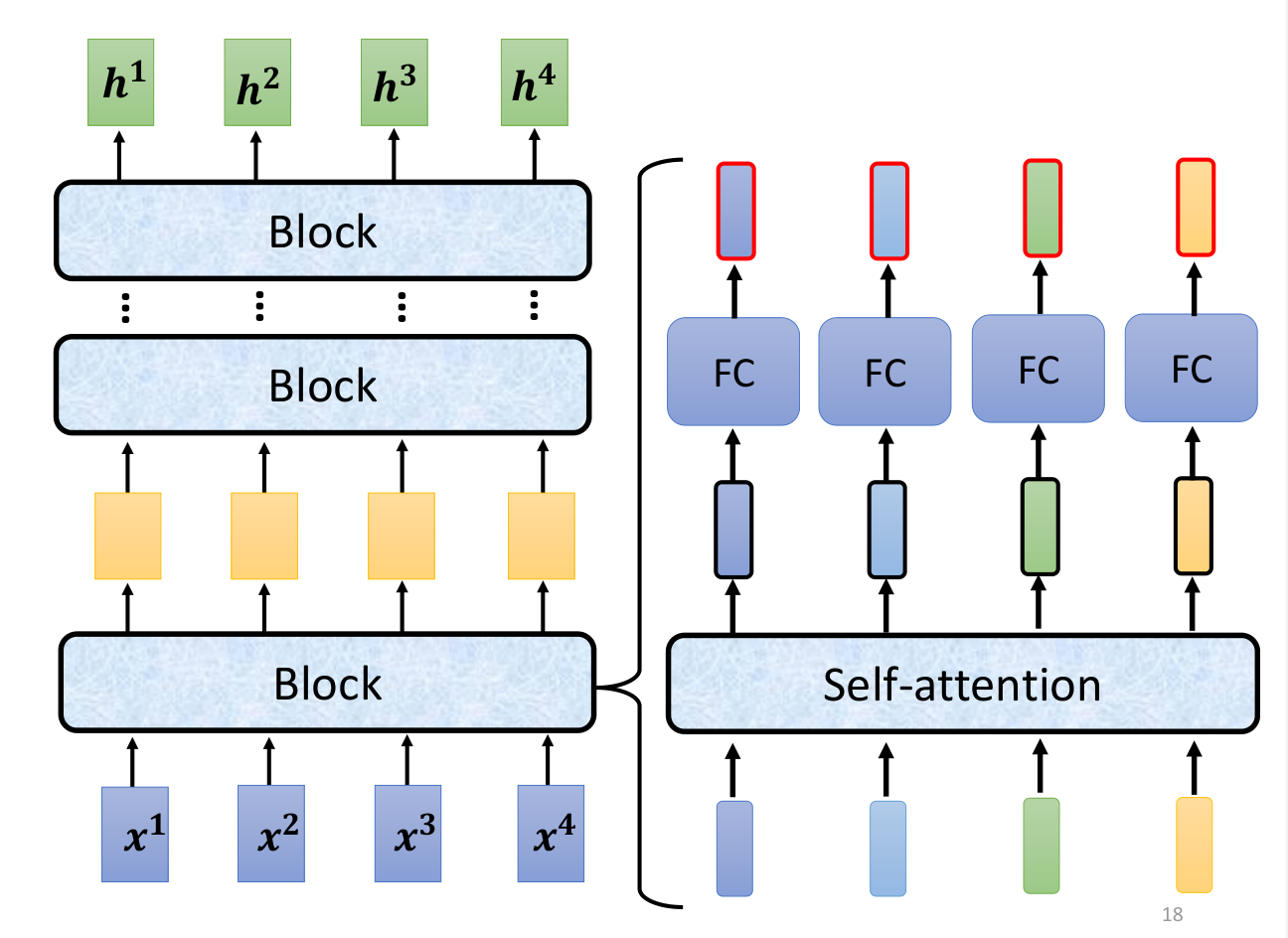
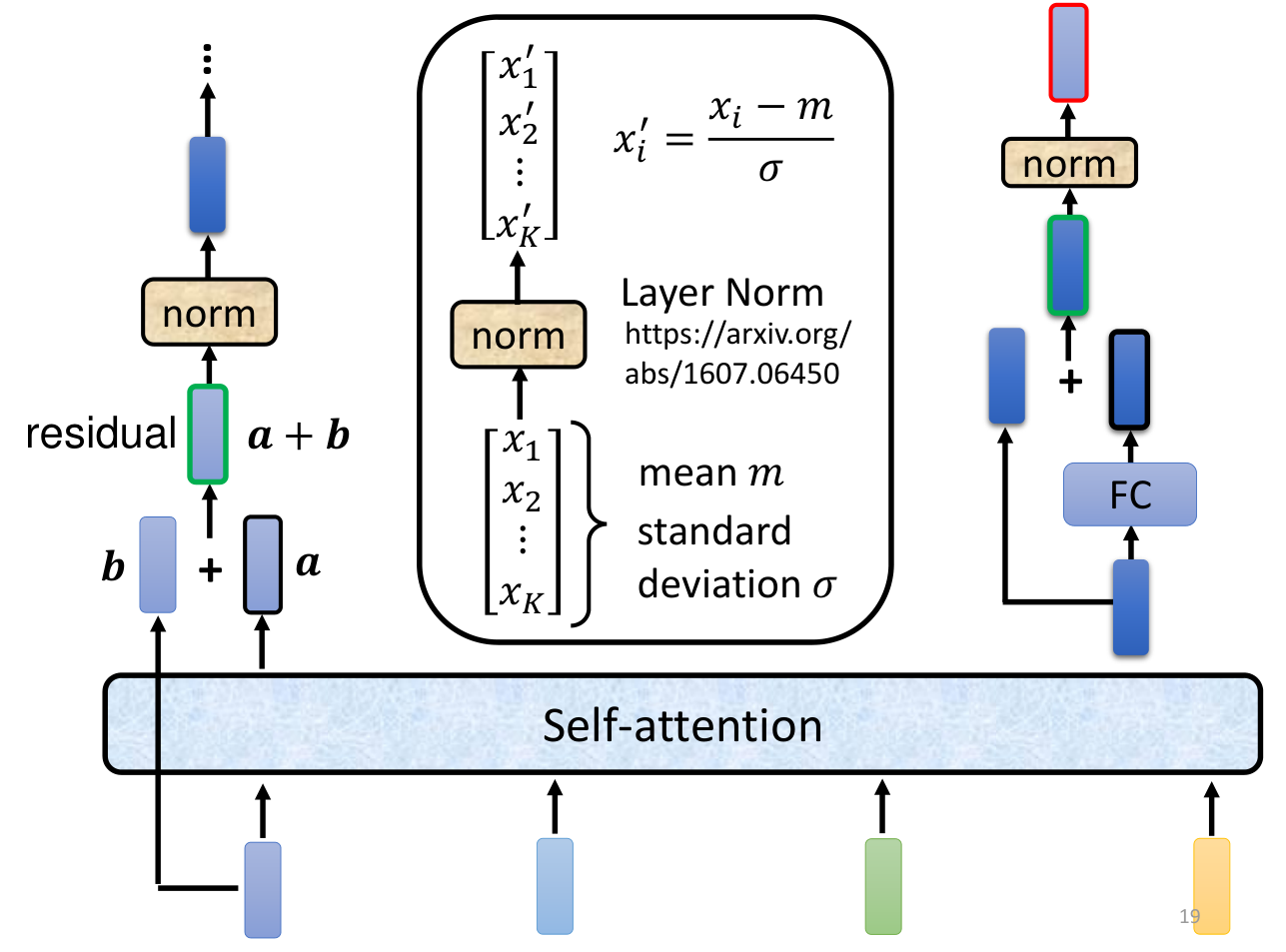

深绿色的表示Embedding层的输出,加上代表Positional Embedding的向量之后,得到最后输入Encoder中的特征向量,也就是浅绿色向量。然后再经过self-attention层变为。然后进行一个残差连接,与进行相加,解决梯度消失的问题,再进行Layer Normalization,得到深粉红色的。然后再经过一个前馈神经网络(线性变化 + ReLU + 线性变化),进行残差连接,再进行Layer Normalization,得到。这样就得到了Encoder的输出。
transformer的encoder部分并不是最优的,还有一些其他的改进可以比transformer达到更好的效果。
Decoder
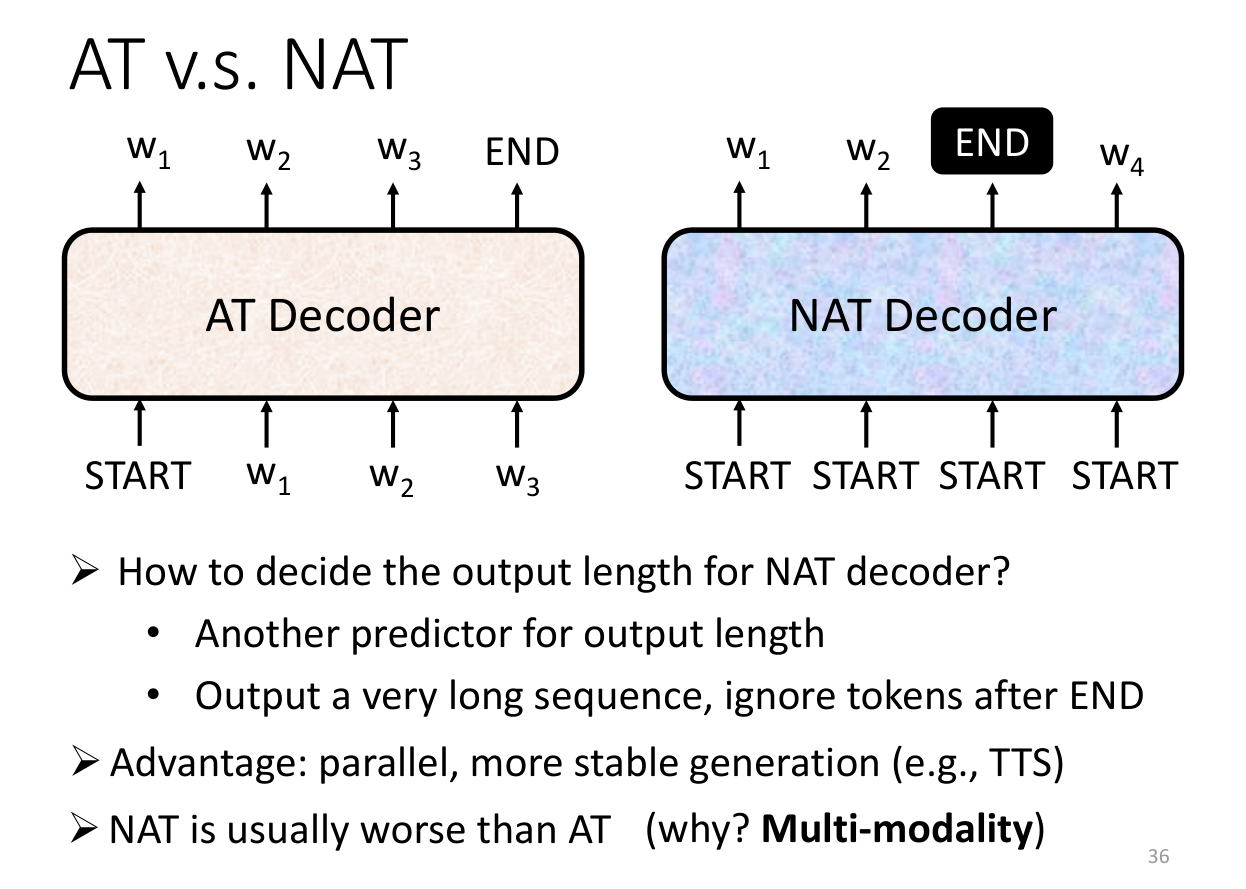
Decoder部分其实有两种,一种是Auto-regressive,一种是Non-Auto-regressive。Auto-regressive是指在生成下一个词的时候,需要依赖之前的词,而Non-Auto-regressive是指在生成下一个词的时候,不需要依赖之前的词。
Auto-regressive
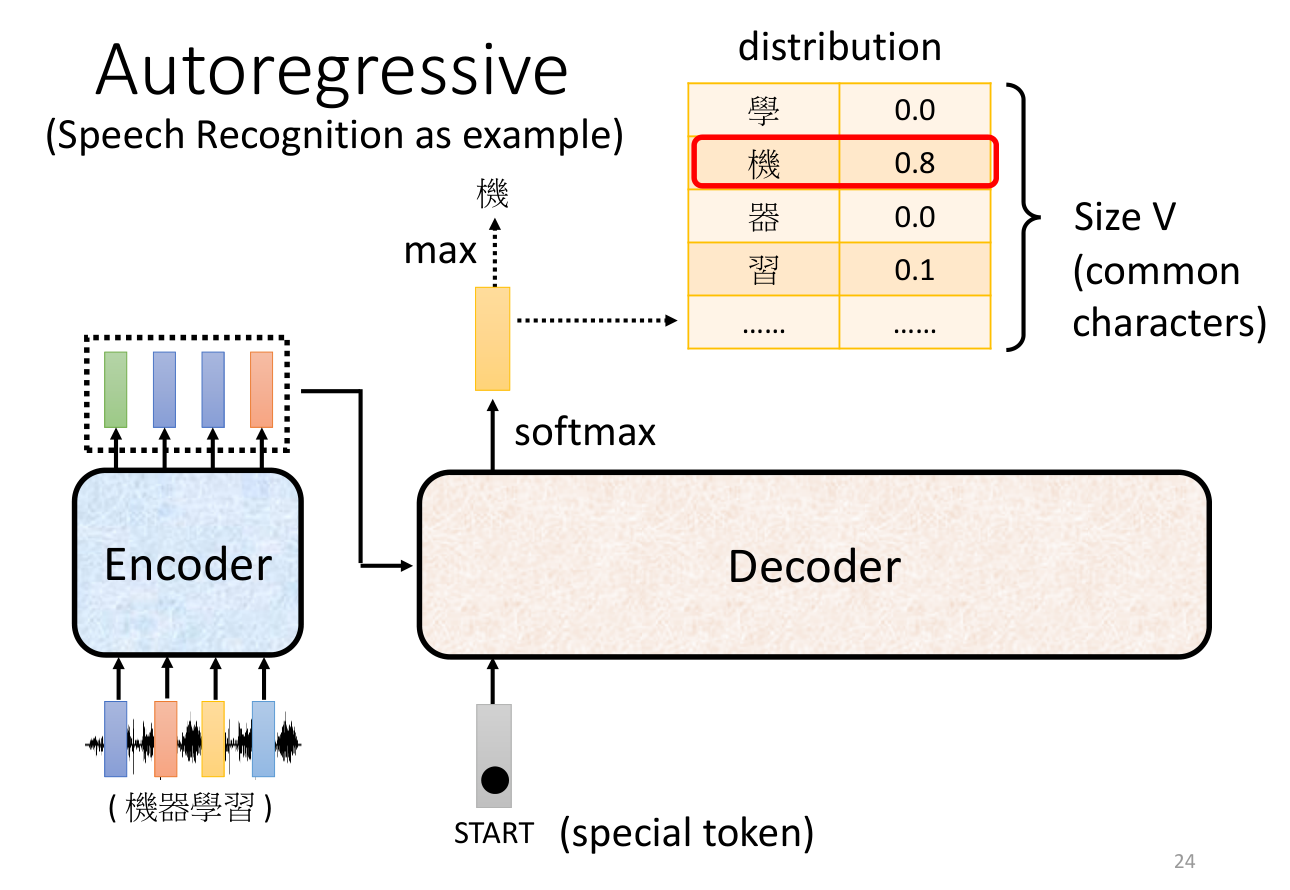
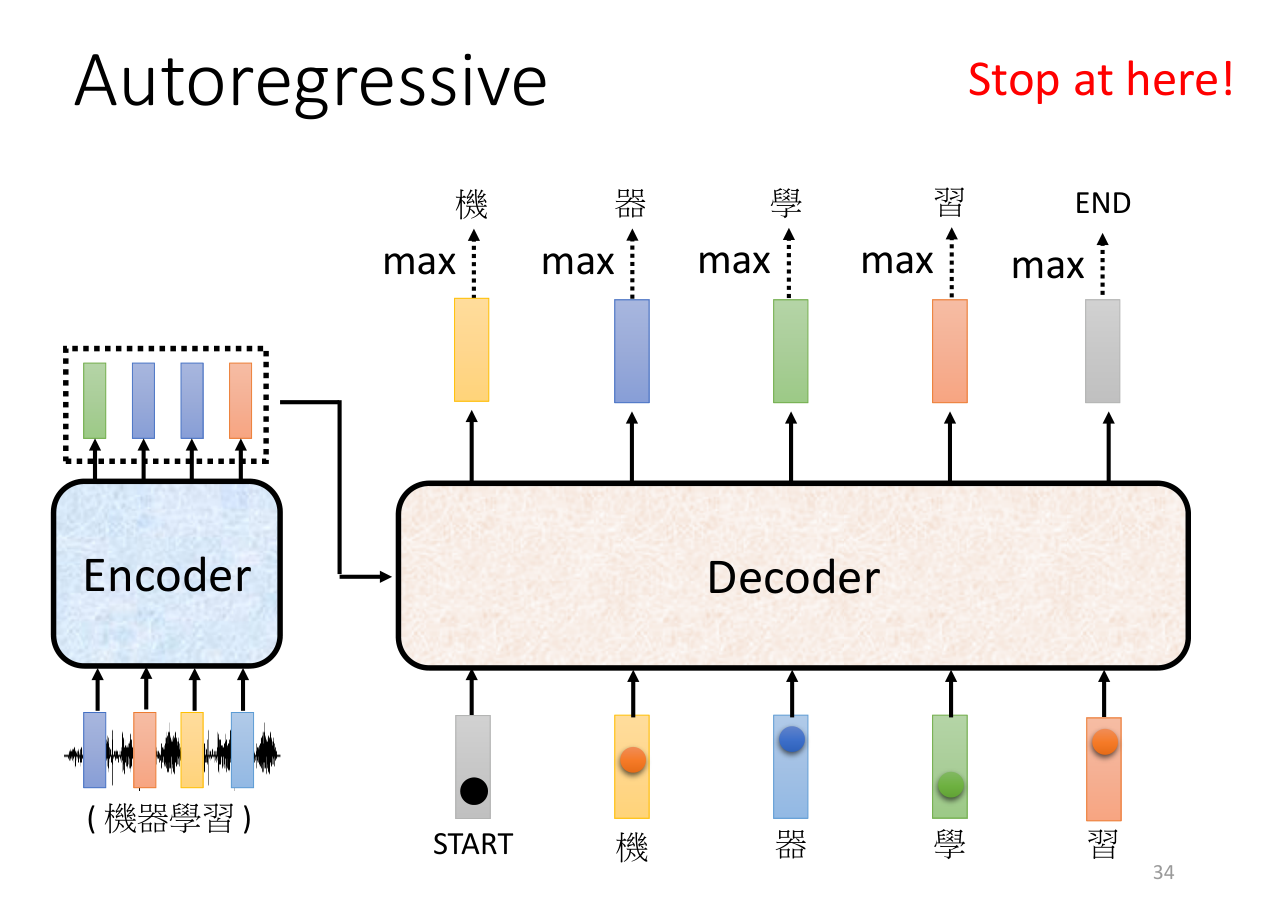
如上图所示,输入为一个开始讯号,然后输出为一个词表中预测概率最高的字,上图中这个字为“机”。
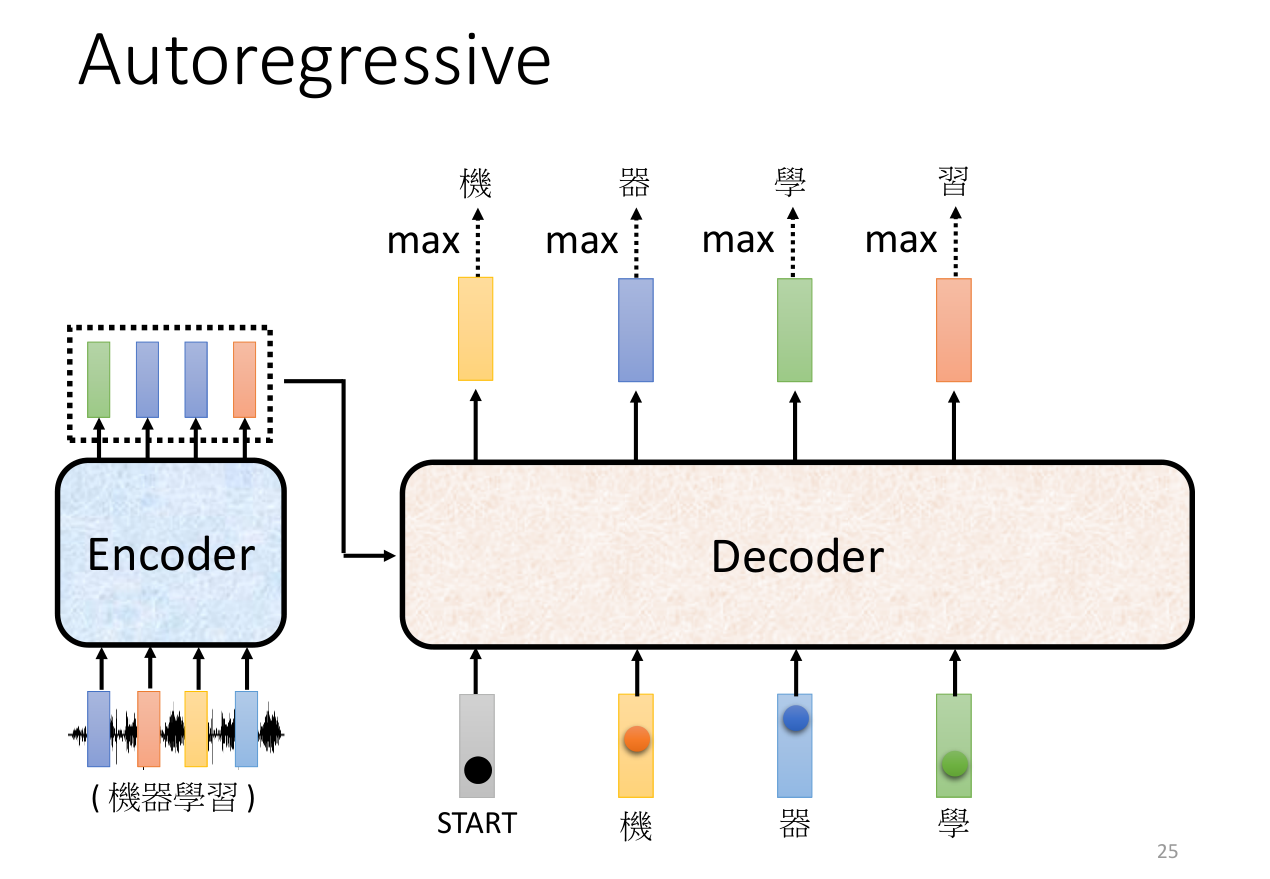
输出的字作为下一个时刻的输入,然后再次输出一个字,如此循环。例如得到了“机”之后,再将“机”作为输入,得到“器”,再将“器”作为输入,得到“学”,重复操作,直到得到结束讯号。
这样有一个问题,如果前面的词预测错误,那么后面的词也可能会预测错误,造成一步错步步错的情况。
Decoder部分的详细结构如下
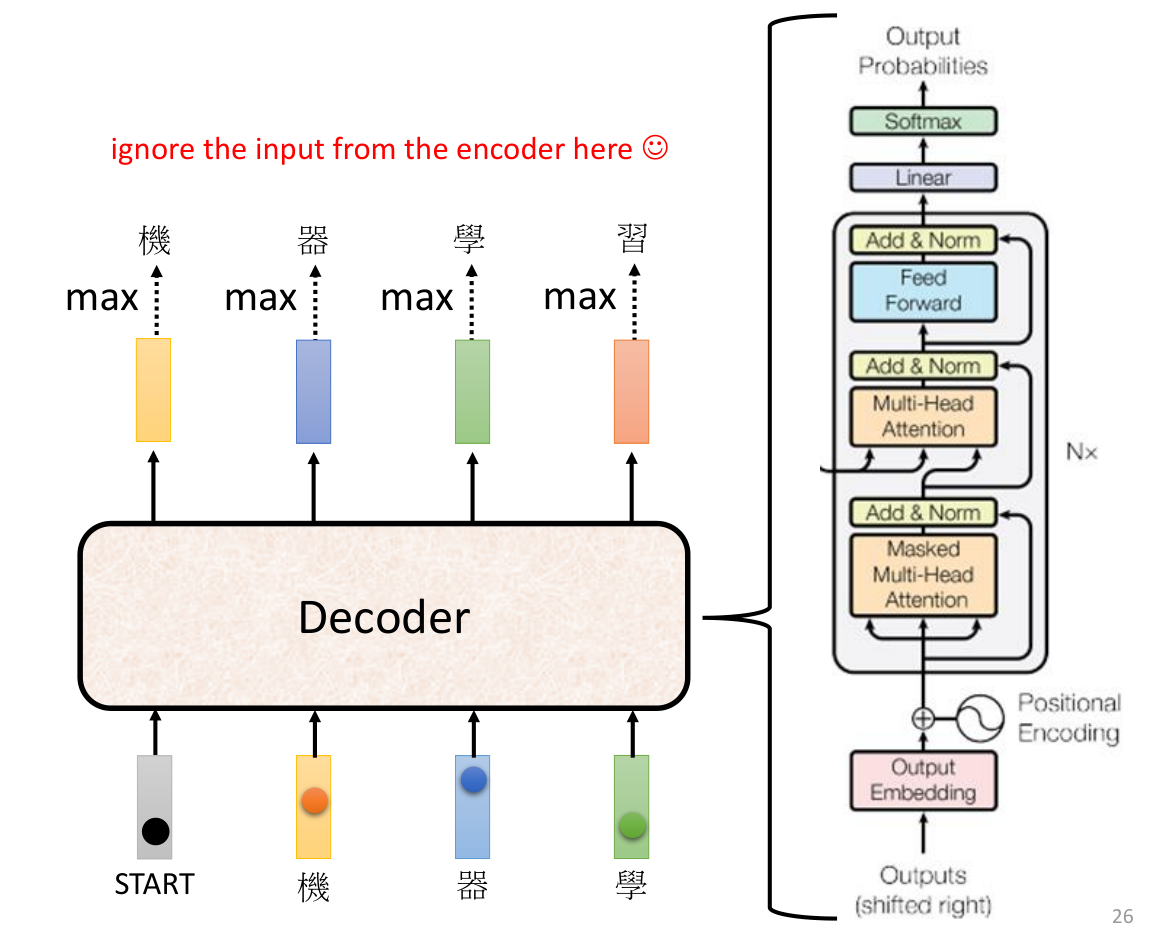
masked self-attention是指在decoder部分,只能看到当前时刻之前的词,不能看到当前时刻之后的词。masked self-attention的作用是为了让训练和预测的时候保持一致,因为在预测的时候,是不能看到当前时刻之后的词的。masked self-attention的结构如下:
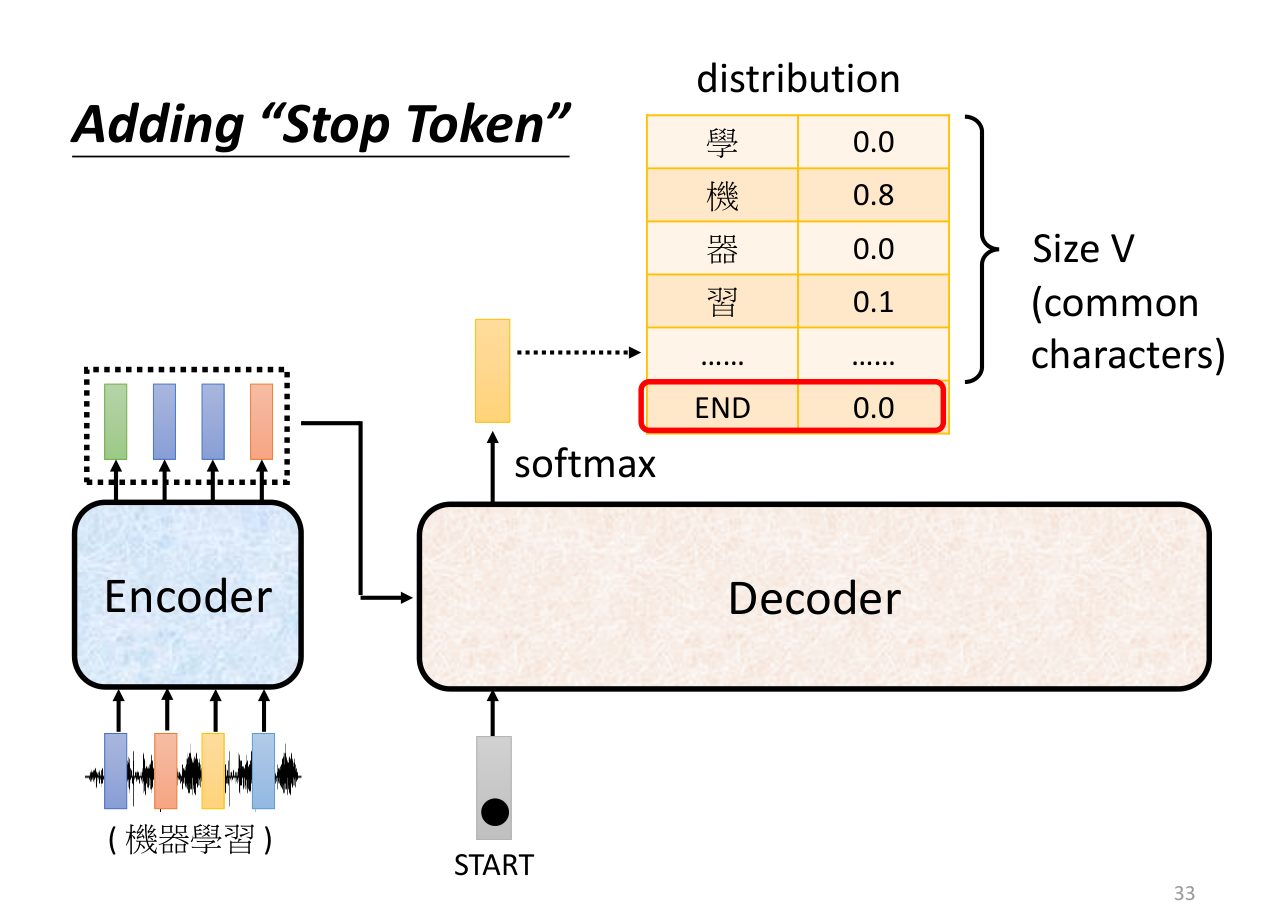
添加结束讯号来结束当前输出
Non-Auto-regressive
Non-Auto-regressive是指在生成下一个词的时候,不需要依赖之前的词。这样就可以并行计算,提高效率。
encoder-decoder结合
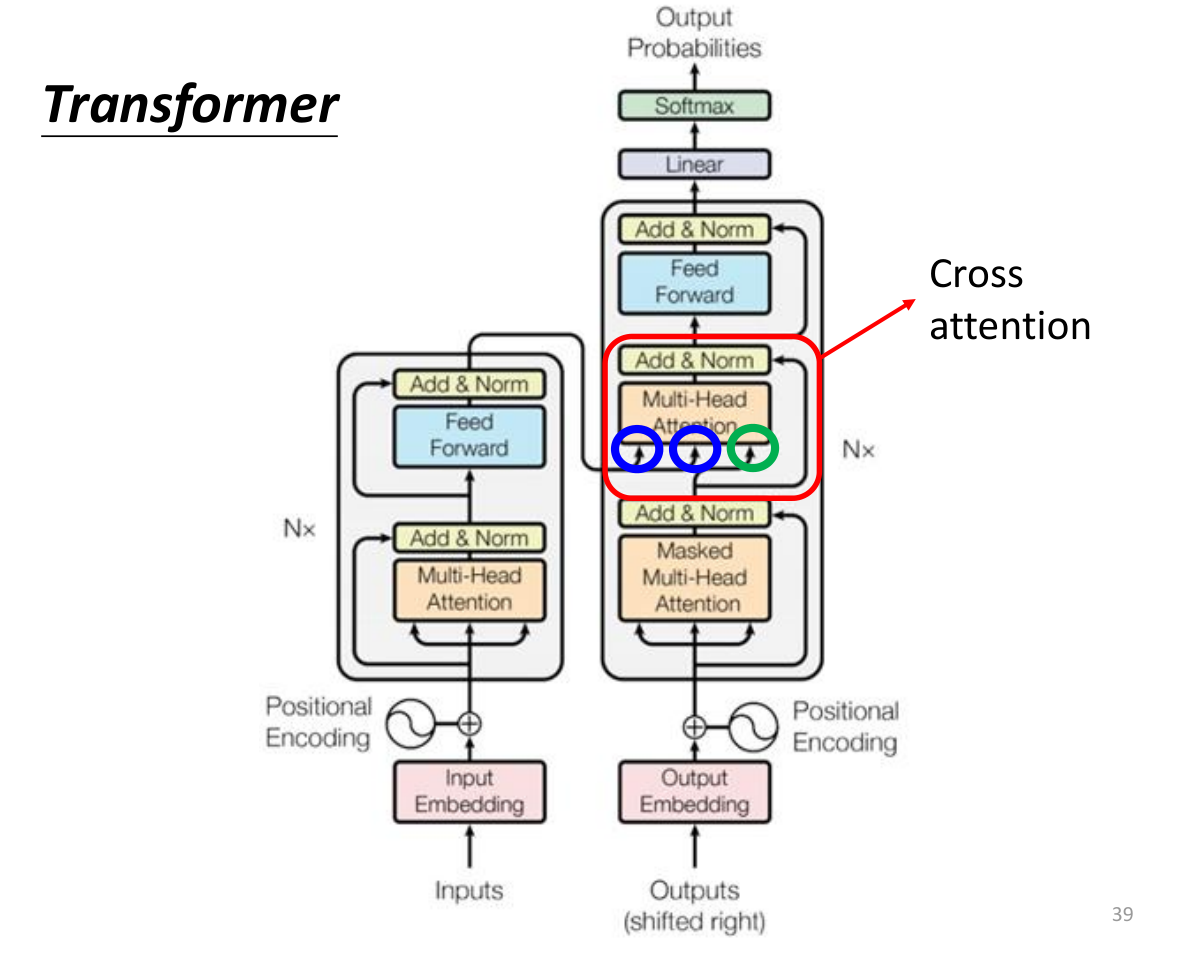
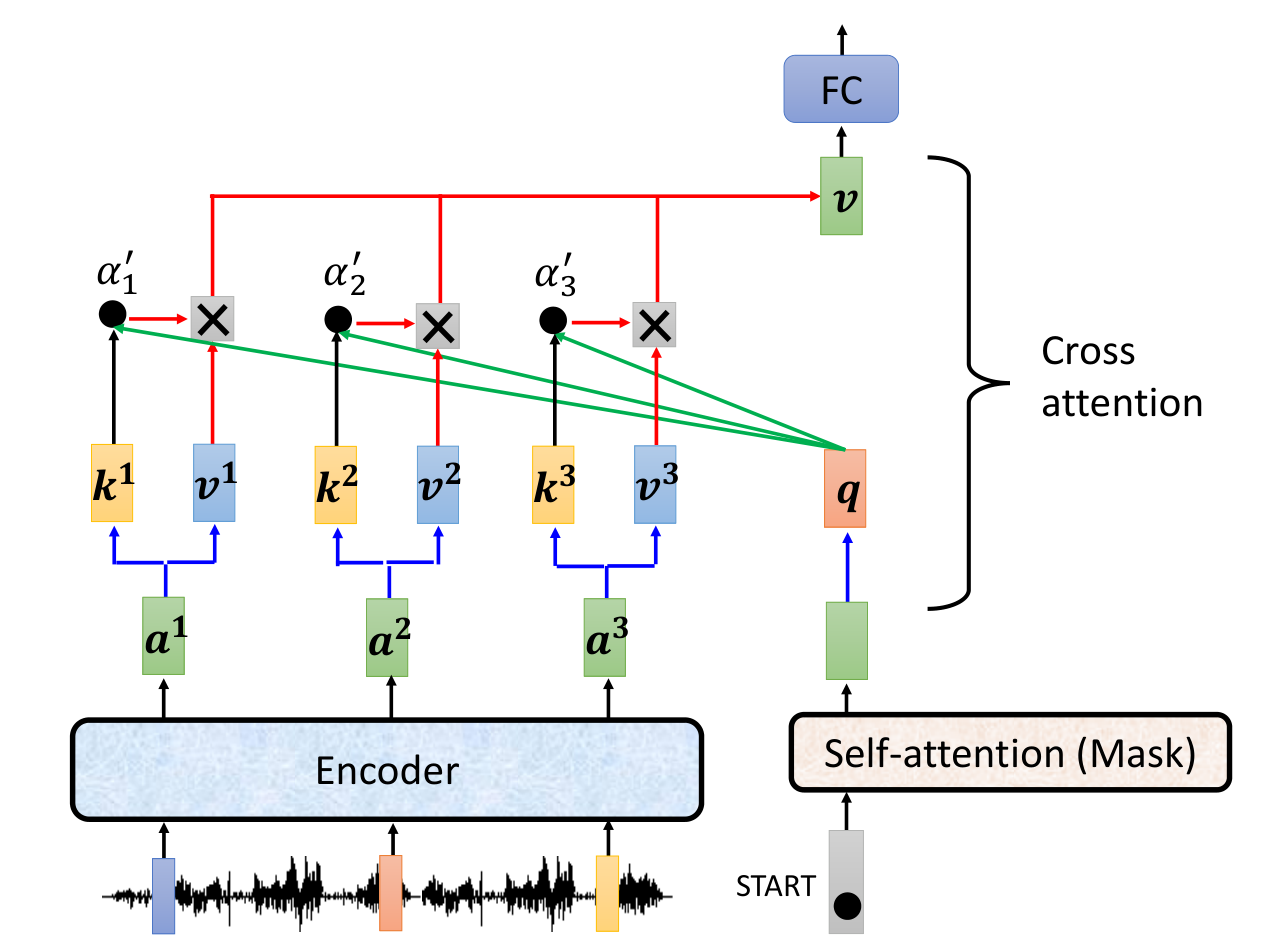
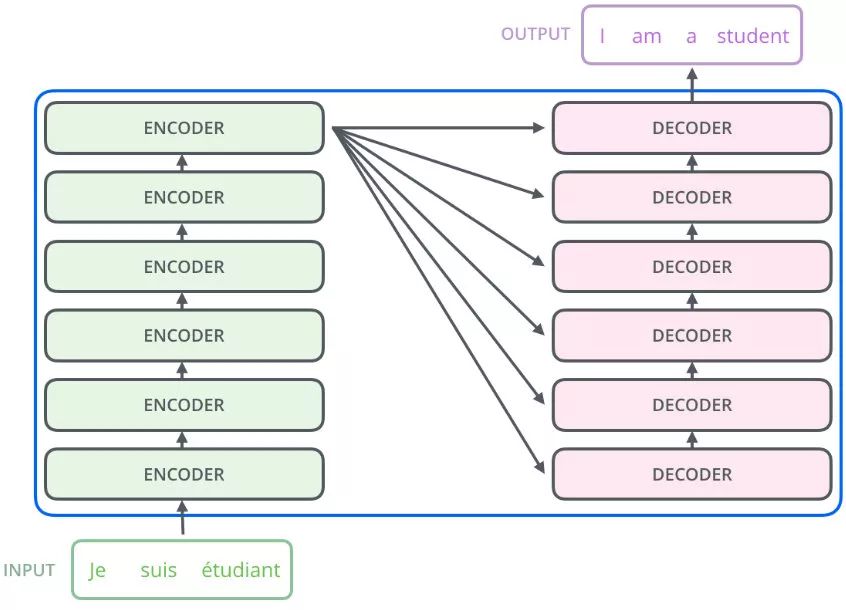
不一定要把encoder最后一层的输出输入到decoder,也可以尝试其他的方式,如下图所示