Swin Transformer
Swin Transformer
Swin Transformer通过在一系列视觉任务上的强大表现,进一步证明了Transformer模型在计算机视觉领域的有效性。
Swim Transformer的核心思想是提出了hierarchical transformer以及Shifted Windows。
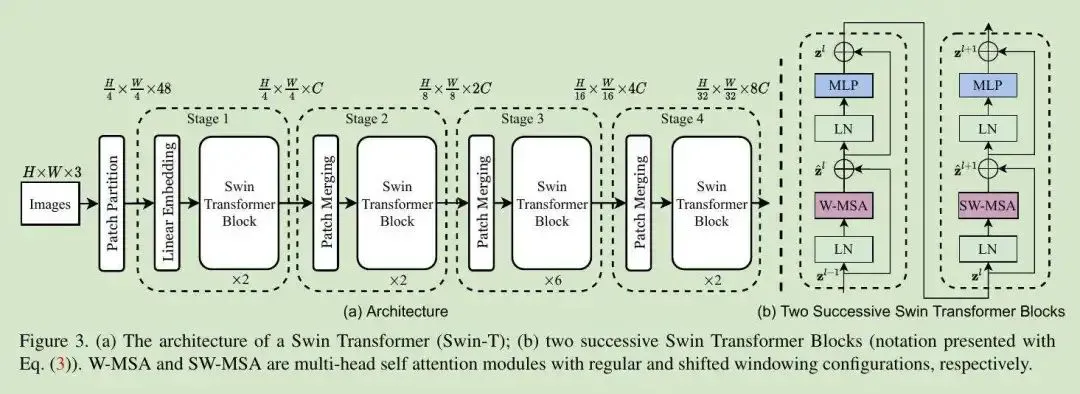
Swin Transformer不同于ViT始终在全局上计算注意力,Swin Transformer的自注意力计算是以窗口为单位计算的,这相当于引入了聚部聚合的信息,和CNN卷积过程类似,但是步长和卷积核的大小一样,这样就使得每个窗口不会重合,每个窗口得到一个值,代表该窗口的特征,然后经过patch merging的操作,将窗口进行合并,在继续对该合并后的窗口进行自注意力计算。这样使得Swin Transformer能够处理大尺度的图像,同时保持较低的计算复杂度。Swin Transformer的结构如下图所示:
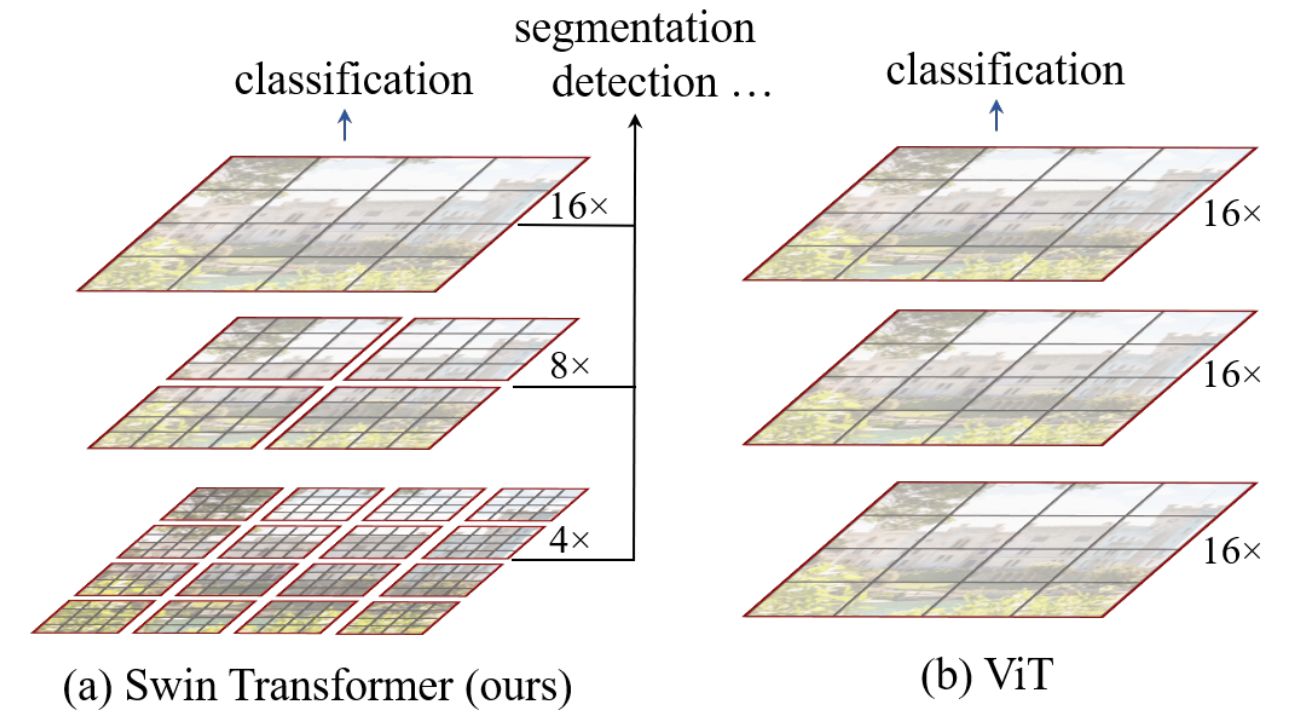
Swin Transformer是一个通用的网络架构,不仅能做图像分类,还能做一些密集预测性任务。
Shifted Windows
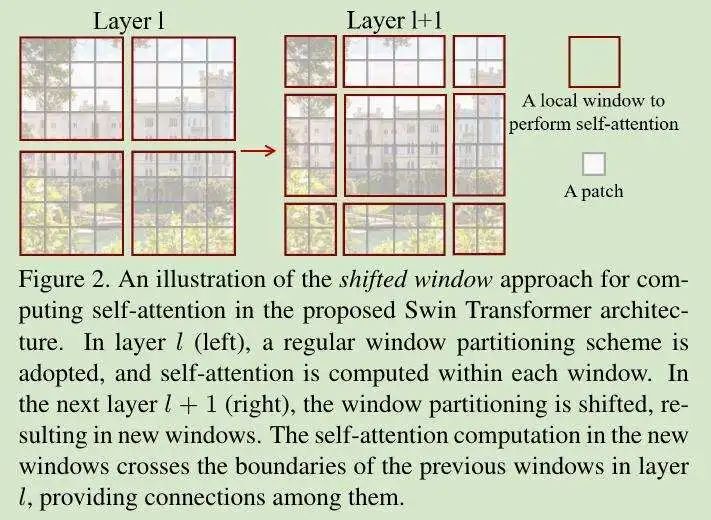
首先在Layer1计算自注意力,然后使用Shifted Windows的方法,将特征图进行移位,比如向右下角移动两个单位,得到了Layer1+2的特征图,然后再计算自注意力,这样使得每个小patch本身的感受野拉大了,能够注意到其他窗口的信息了,使得窗口和窗口之间可以进行信息交流(cross-window connection)。最后进过patch merging合并到最后几层之后,每一个patch的感受野就变得很大了,能够感受到大部分图像的信息。将局部注意力转化为全局注意力,既节省了内存,效果又很好。
cyclic shift
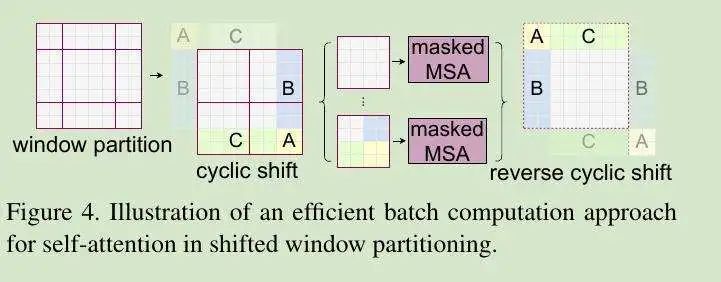
由于Shifted Windows的方法,使得每个patch的大小都不一样,为了方便进行批处理操作,采取了cyclic shift的操作。由于cyclic shift的操作使得不相邻的窗口变得相邻起来,我们需要在计算自注意力的时候加入掩码操作,让每个窗口合理的计算自注意力,最后再把算好的自注意力还原,使用reverse cyclic shift操作。
Patch Merging
该模块的作用是在每个Stage开始前做降采样,用于缩小分辨率,调整通道数,调整通道数进而形成层次化的设计,同时也能节省一定的运算量。下面是示意图:

其实本质上就是对图像进行缩小并完成降采样的操作,类似CNN中每个Stage开始前用stride=2的卷积/池化层的操作。在Swin Transformer中就是通过间隔2来选取元素的操作,并concat到一起,作为一个张量,最后通道数是原先的4倍。

最后在通过一个全连接层在调整通道维度为原来的两倍。
Swin Transformer块
Swin Transformer中使用的块用Window MSA(W-MSA)和Shift Window MSA(SW-MSA)模块取代了ViT中使用的标准多头自注意力(MSA)模块,如下图所示:
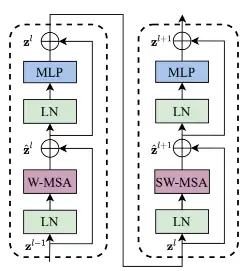
Swin Transformer块有两个子单元。第一个单元使用W-MSA,第二个单元使用SW-MSA,每个子单元由一个规范化层,一个注意力模块,另一个规范化层和一个MLP层组成。这也是Swin Transformer整体架构中为什么Swin Transformer Block的个数都是偶数。