
Vision Transformer
Vision Transformer
在深度学习领域,卷积神经网络(CNN)是处理图像任务的主流模型。然而,CNN的局限性在于其固定的局部感受野和全局池化操作,这使得CNN在处理长距离依赖的任务上表现不佳。而自然语言处理领域,由于序列模型(如LSTM、Transformer)的成功应用,使得人们开始思考是否可以将序列模型应用到图像领域。因此,Vision Transformer(ViT)应运而生。
方法
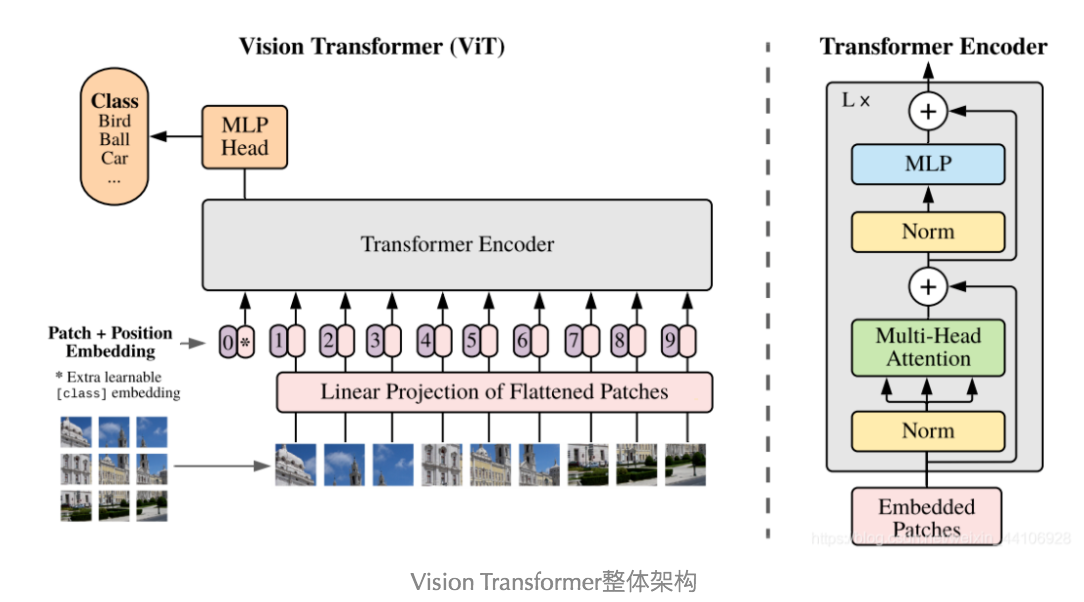
ViT的核心思想是将图像分割成固定大小的图块,然后将这些图块展平成一维向量,作为输入序列。然后将这些序列输入到Transformer模型中,通过多层的Transformer模型来学习图像的表示。ViT的结构如下图所示:
可以看到,基本上就是原始的Transformer Encoder模型,只是将输入从文本序列变成了图像序列。将图片大小分割成固定大小的图块,然后将这些图块展平成一维向量,加入位置编码信息,然后输入到Transformer模型中。位置编码采用了Bert的思想,位置编码是通过模型学习得到的,并且在输入序列的开头默认加入了一个特殊的CLS token(类似于Bert中的[CLS]),用于表示整个图像的信息。下游任务可以使用CLS token的输出,经过一定的变化,来进行完成特定的任务。比如分类任务,可以直接使用CLS token的输出,然后通过一个MLP来完成分类任务。
其实ViT的思想早就有人写过论文了,只不过是在小的数据集上,图像大小为3232,分成的patch大小为22,然后输入到Transformer模型中。但是由于计算资源有限,所以没有扩展到大数据集上,直到ViT的出现,让该思想在大数据集上得到了很好的效果,引起了人们的关注。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Fms231!
