
GPT
GPT
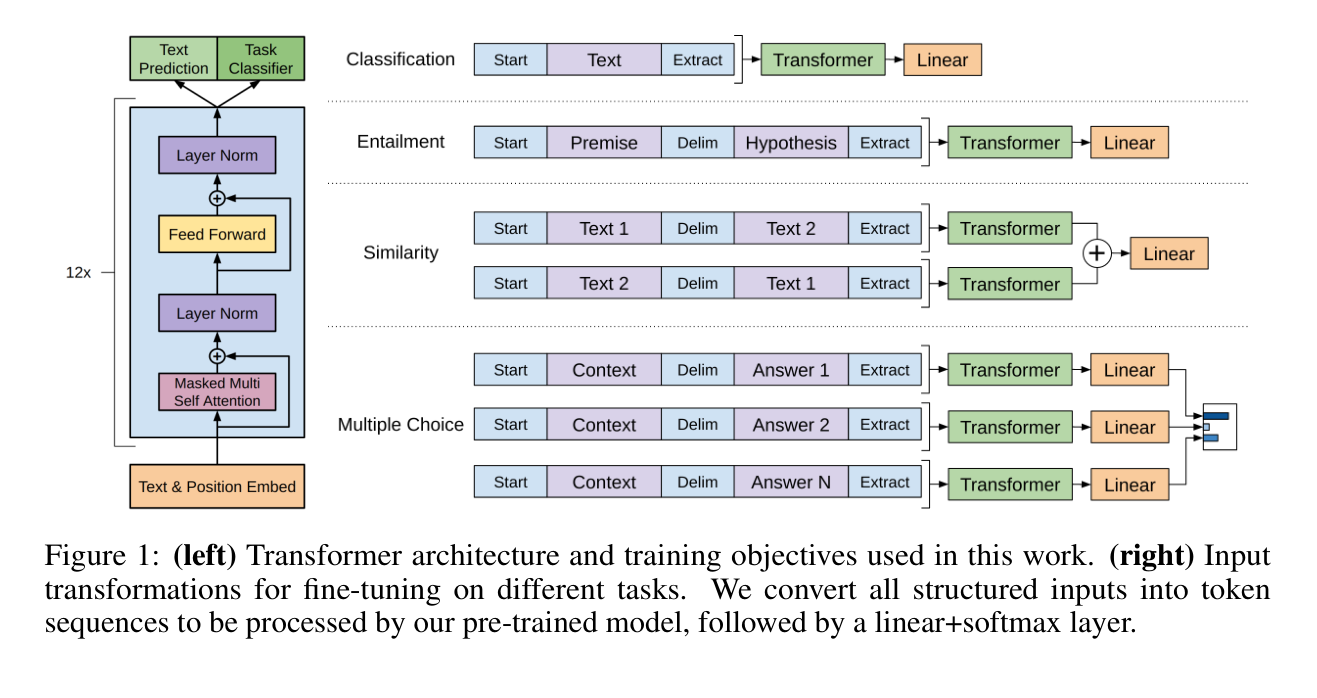
无论下游任务发生什么变化,Transformer层是不会变的,只需要改变输入输出层即可。GPT就是一个预训练模型,之后根据下游任务的不同进行fine-tuning即可
GPT-2
GPT-2是GPT的升级版,模型更大,参数更多(15亿),效果更好,主要是讲解zero-shot learning。
GPT-3
meta learning:训练了一个很大的模型,泛化性很不错。
in-context learning:在上下文中学习,即使有训练样本,也不会更新权重。
Codex:GPT-3的应用
Megatron-LM:将模型使用的张量拆开,分别在不同的GPU上进行计算,然后再相加合并。达到模型并行的效果。用于transformer模型的训练。
Zero:数据并行实现大模型的训练。
DALL·E 2:文本经过clip变成文本特征,文本特征进过prior变成图片特征,图片特征进过decoder变成图片。zero-shot
ViLT
Chain of Thought:

写上中间推理过程,然后再问模型答案。
let’s think step by step.
Instruct GPT:
Text-to-Image:
- GAN
- AE DAE VAE VQVAE
- Diffusion Model
- DALL·E2
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Fms231!
