
CLIP
CLIP
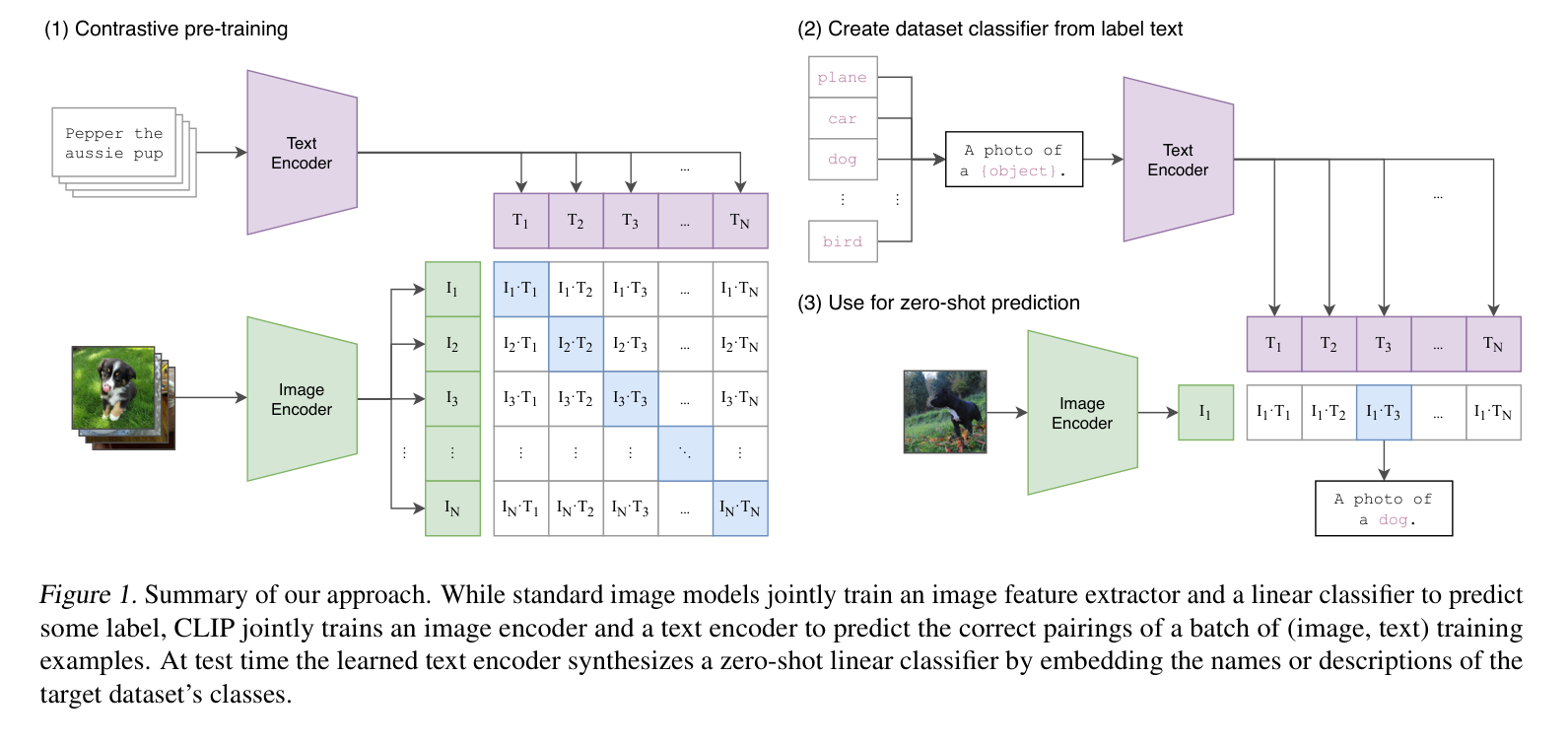
模型架构分为两部分,图像编码器和文本编码器,图像编码器可以是比如resnet50/ViT,然后文本编码器可以是transformer。
训练数据是网络社交媒体上搜集的图像文本对。在训练阶段,对于一个batch的数据,首先通过文本编码器和图像编码器,得到文本和图像的特征,接着将所有的文本和图像特征分别计算内积,就能得到一个矩阵,然后从图像的角度看,行方向就是一个分类器,从文本角度看,列方向也是一个分类器。
而由于我们已经知道一个batch中的文本和图像的匹配关系,所以目标函数就是最大化同一对图像和文本特征的内积,也就是矩阵对角线上的元素,而最小化与不相关特征的内积。这也就是对比学习的思想,最大化同类之间的相似度,最小化不同类之间的相似度。正样本是同一对图像和文本的特征,负样本是不同的图像和文本的特征。
对于这样的无监督的预训练方式,比如对比学习,是需要大量的数据的,所以OpenAI专门收集了4亿个图片和文本的配对,而且该数据清理的非常好,质量特别高。
Zero-shot
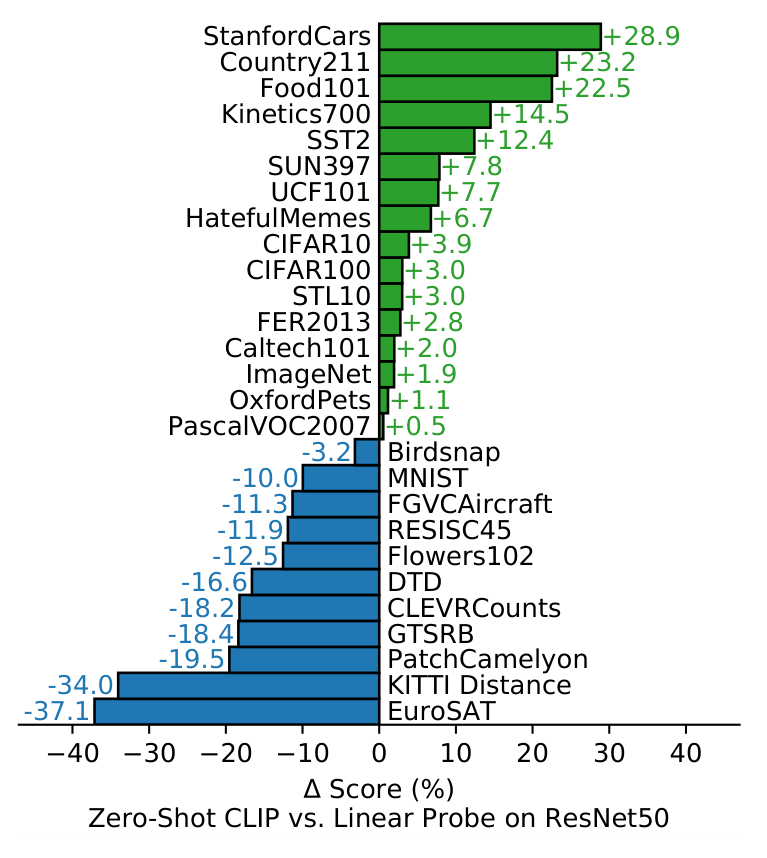
OpenAI的CLIP模型还是zero-shot的,也就是说,它可以在没有训练的情况下,直接在新的任务上进行预测也可以取得不错的效果。并且OpenAI提出了迁移学习的效果随着模型的规模增大而增大。
Prompt Engineering
由于只使用标签可能会出现多义词的问题,所以OpenAI提出了Prompt Engineering的方法,也就是通过设计一些提示样本,来引导模型学习。比如CLIP模型在ImageNet上的表现,就可以通过设计一些提示样本来引导模型学习,比如“a photo of a
在特定数据集上训练
CLIP虽然是一个zero-shot的模型,但是OpenAI为了提高CLIP在特定数据集上的效果,采取了让CLIP继续训练。主要方式是linear probe,也就是在CLIP的基础上,加上一个线性分类器,然后在特定数据集上进行训练(只改变linear probe的参数,CLIP的模型参数freeze),并没有采用fine-tuning的方式,在整个模型上进行微调。
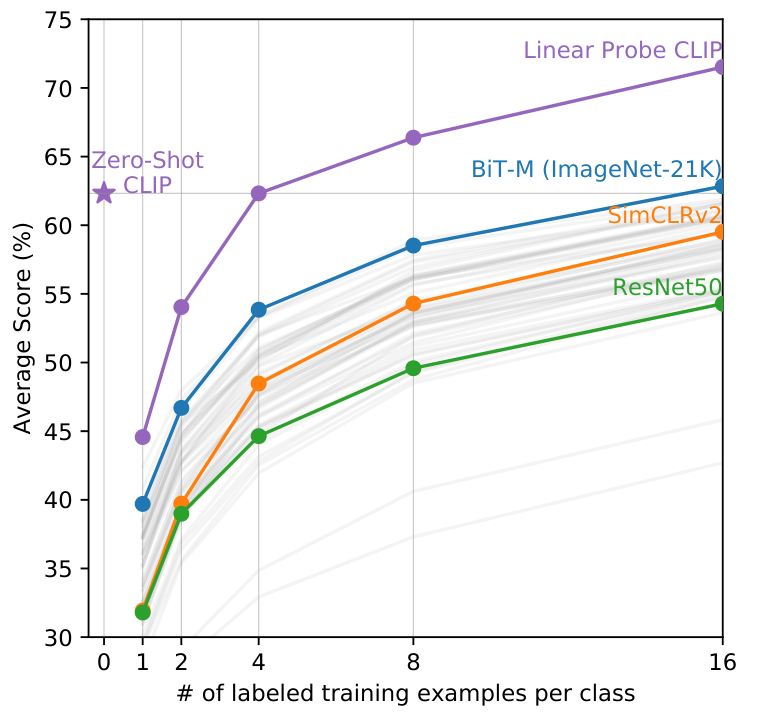
泛化性
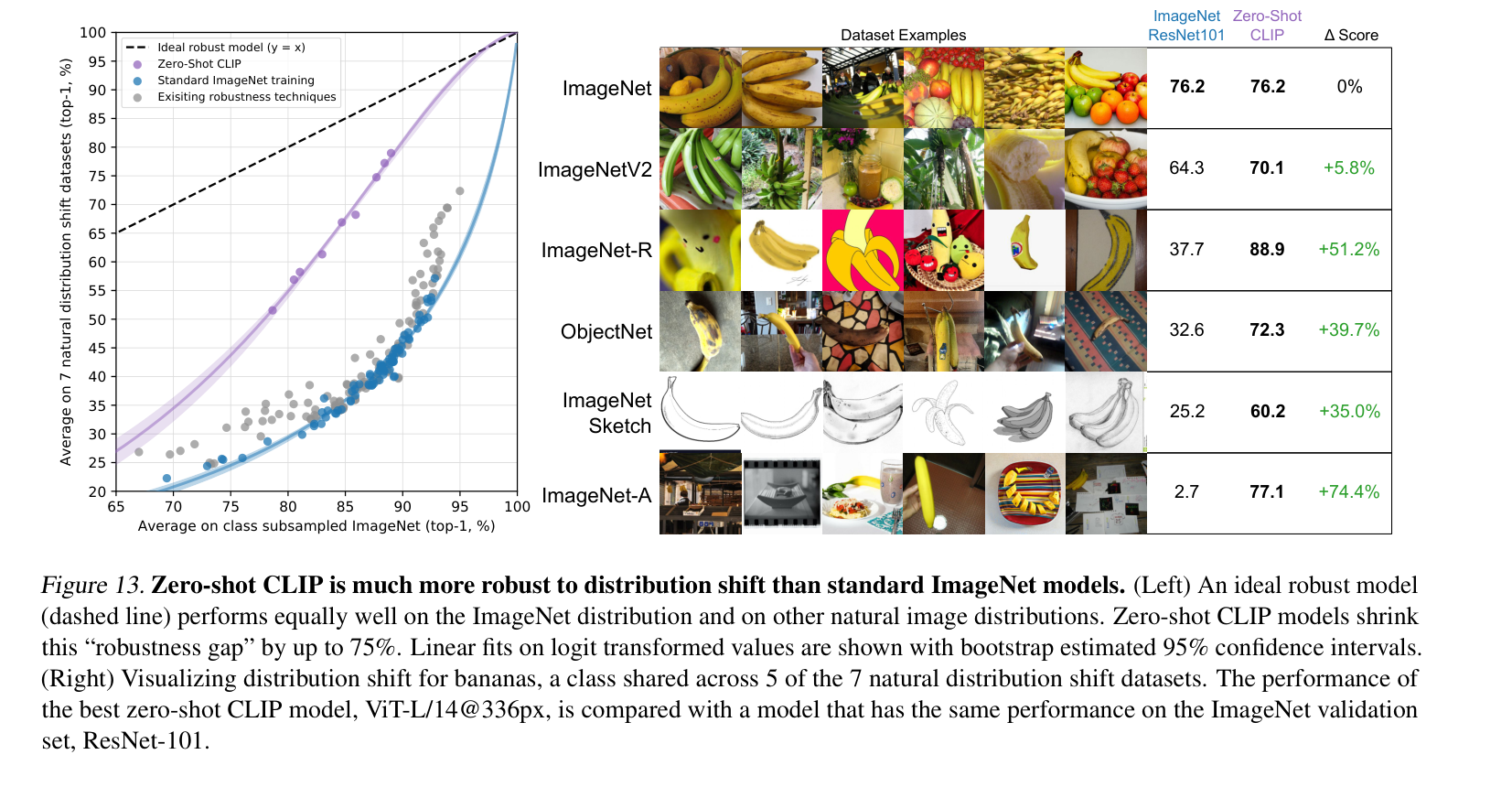
CLIP模型鲁棒性强,泛化性强,能够在不同的数据集上取得不错的效果。
基于CLIP可以自由定义自己的分类器,而且与现有的很多工作结合或许玩出很多花样,比如DALL·E中用到了CLIP,又比如有人已经把CLIP和stylegan结合来生成图片,又或者可以和GPT-3结合等等。
